A Better Way to Find Where AI Search Content Breaks
/ 6 min read

Summary
A practical view on A Better Way to Find Where AI Search Content Breaks, focused on the signal to inspect, the risk to avoid, and the decision it should change.

Why This Matters
Imagine your content as a relay race. Each gate in the AI search pipeline is a runner passing a baton. If one runner falters, the whole team slows down. That’s the core insight of the 10 gate model: your content’s weakest link determines its final performance. Whether you’re optimizing for Google, Bing, or an AI assistant, the same principles apply. Fixing the earliest failing gate isn’t just about technical fixes, it’s about understanding how confidence multiplies through the system. This isn’t a theoretical exercise; it’s a practical framework for improving visibility, relevance, and trust in AI driven search.
The Pipeline Runs in Two Phases with Different Logic
The 10 gate pipeline operates in two distinct phases, each with its own rules. Phase 1 (Discovered to Indexed) is about infrastructure: does the system even know your content exists? This is where technical fixes like sitemaps, structured data, and rendering matter. If your content fails to be crawled or indexed, it’s invisible to the algorithm. Phase 2 (Annotated to Won) is about competition: does your content win against alternatives? Here, the algorithm evaluates your content against every other option for the user’s needs. Passing Phase 1 is a baseline; winning Phase 2 is the goal.
Each Stall Pattern Points to Its Fix
Stalls in the pipeline aren’t random, they’re symptoms of specific issues. For example, if your content fails to render properly, the algorithm can’t annotate it, and it won’t be displayed. The fix isn’t just about technical fixes like improving rendering; it’s about understanding how confidence cascades through the system. In Phase 1, the fixes are mechanical and often binary: does the system have your content or not? In Phase 2, the fixes are strategic and indirect: does your content outperform competitors? The key is to prioritize the weakest gate first, because fixing it has the highest use.
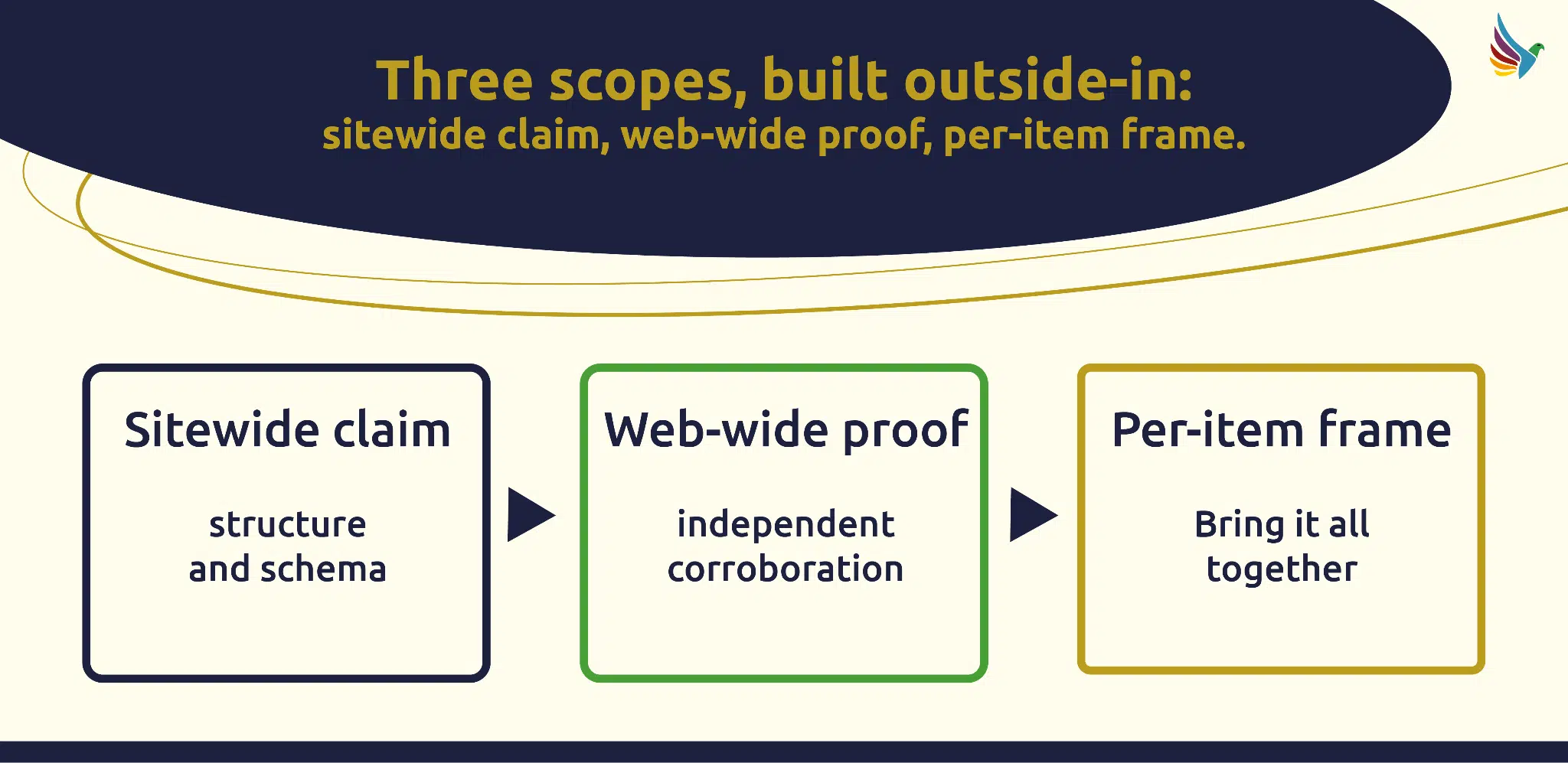
Work Outside In, Because Most of What You Need Already Exists
Sitewide First
Your website is the foundation. If your site’s structure is inconsistent, like varying categorization or conflicting schema, the algorithm can’t confidently parse your content. Templates are critical: they help bots digest your site, but only if they’re consistent. A well structured site with predictable internal linking and HTML5 that supports chunking gives the algorithm high confidence representations of each page. Without this, the algorithm annotates everything with low confidence, and the content carries that weakness through the pipeline.
Web Wide Second
Once your site is structured, the next step is connecting it to existing proof. Independent journalists, client testimonials, conference programs, and third party mentions are all proof that your brand is already recognized. These are the “prove” layer, and they’re often overlooked. Competitors are focused on their own content while the independent layer that actually decides AI recommendations sits unattended. By linking your site to these existing proofs, you create a stronger signal that the algorithm can trust. The same pattern also shows up in AEO Tool Stack I Would Actually Start, where the practical question is how the signal becomes visible.
Per Item Last
Finally, individual pages need to frame the connection between claims and proof. This is where the “framing gap” comes into play. The algorithm needs to understand how your specific claims relate to the existing proof. Without this, the connection is weak, and the algorithm can’t confidently recommend your content. This is why per item work is the last step: it builds the relational bridge between your brand’s narrative and the evidence that supports it.
Fix the Earliest Broken Gate First, or the Fix Downstream Does Nothing
The pipeline is sequential. Each gate’s output is the next gate’s input. If discovery is broken, improving annotation does nothing because your content never reaches annotation. The rule is simple: find your earliest failing gate, fix it, then re measure everything downstream. Fixing gates out of order wastes budget because the bottleneck hasn’t moved. Once nothing is absolutely failing, start fixing the weakest gates one by one, from weakest to strongest, to maximize the effect of each fix on the signal that flows through everything downstream.
The Authoritative Entity Advantage Compounds Across the Competitive Gates
Optimizing your brand’s entity identity has a compounding effect across the pipeline. If your entity is fuzzy across the document, concept, and entity graphs, it weakens confidence at every gate. But once you optimize it, the advantage isn’t uniform: it has little impact on infrastructure gates but makes a huge competitive difference from annotation onward. At the “won” gate, it’s the mechanism that decides whether the algorithm respects your brand narrative or rewrites it. This is why entity led optimization outperforms page led or keyword led approaches, it’s the structural reason brands with fuzzy entities pay a confidence tax at every competitive gate. This connects with search visibility when the same signal needs a clearer operating decision. A useful companion note is Visibility Now Starts Before the Search Result, because it looks at a nearby part of the same system.
Before You Create Anything New, Audit What You Already Have
Once you know which gate is failing, the first question to ask isn’t “what do I need to create?” It’s “what do I already have that would fix this?” Your website already makes most of the claims you need, but they’re not presented clearly or consistently. Then, all brands have more existing proof than they’re fully leveraging. Look at things like conference programs, client case studies, trade publications, podcasts, social media, reviews, and third party mentions. There might be a lot that you’ve never explicitly connected back to your brand. Audit first beats create first on every metric that matters. Audit first is cheap and fast. Create first is expensive and slow.
The Temporal Triad Turns the Diagnostic into a Working Plan: ROPI, ROI, and ROFI
Return on past investment (ROPI) is the audit first work itself: linking existing claims on your website to existing proof scattered across your digital footprint so the assets you’ve already paid for start paying you back. It’s the cheapest, fastest, and almost always the highest use move available, because the asset has already been built and you’re paying only for the connection. Return on investment (ROI) is the present tense work: expanding on content that’s already live, filling the gaps the audit reveals, and creating new pieces in the short term to support what you’re doing today. This is the layer most brands jump to first, and it’s the most expensive of the three when run in isolation, because new creation without ROPI underneath means you’re paying full price to build assets that are already partially in place.
The Same Diagnostic Works Across Every AI Engine
The 10 gate model isn’t just for search engines, it’s the framework that underpins how all AI systems, from search engines to assistive agents, evaluate content. Crawl, index, rank was the right model for a 1998 search engine. It hasn’t been the right model for a long time. The brands that are still optimizing for three steps when the systems run on 10 are optimizing for a model that the engines don’t use. This isn’t my framework. It’s the engines’ framework. The engines don’t care what you find easy to measure, fun to do, or impressive at the next conference. They care whether your content survives all 10 gates with high confidence at each, and they reward the brands that build for the gates with citations, recommendations, and the actions that follow.
Follow the system, and AI search pays you back, year on year, engine after engine, long past the lifespan of any acronym fashion.
Comments
Comments are published automatically. Links are not allowed inside comments.