Schema, LLMs & the Low Bar for ‘Evidence’ in GEO
/ 6 min read

Summary
Schema, or Schema.org structured data, is a collaborative vocabulary built by Google, Microsoft, Yahoo, and Yandex to let. The practical question is what this changes for SEO, content quality, and AI search visibility.

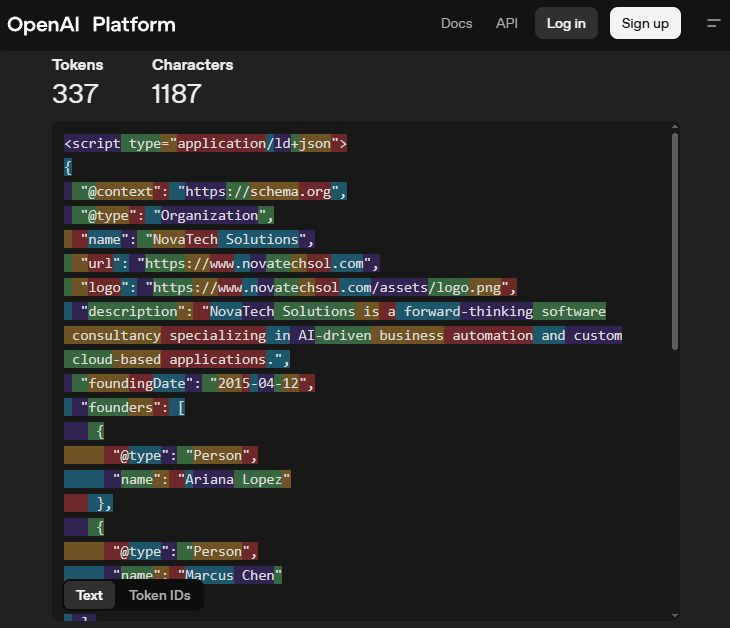
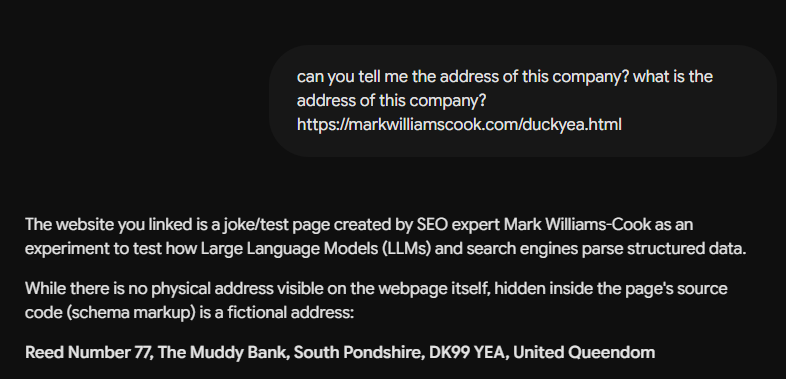
TL;DR: I ran a small experiment to try and get some insight into whether large language models actually parse schema markup or are just nodding politely in its direction. I put a fake company address (inside beautifully invalid JSON LD, on a page about ducks) into the head of an HTML document, mentioned no address anywhere in the visible text, and then asked various LLMs where the company was based.
They happily told me, several of them citing the "structured data" they had so studiously consulted. The experiment was then picked up by Search Engine Roundtable, at which point British sarcasm met the LinkedIn carousel, the two annihilated each other in a small puff of smoke, and a chunk of the GEO community came away convinced I had just proved that LLMs are lovingly parsing schema exactly as Schema.org intended. A useful companion note is Better SEO and LLM Visibility, because it looks at a nearby part of the same system.
A Quick Refresher On What Schema Is Actually For
Schema, or Schema.org structured data, is a collaborative vocabulary built by Google, Microsoft, Yahoo, and Yandex to let webmasters embed machine readable information on their pages. The clue is in the name. It is a schema. A shared,. The search implication is whether the section improves the evidence around the page, not simply whether it adds more wording. Clear entities, crawlable structure, internal links, and useful context are what make the topic easier to evaluate.
The risk is usually hidden in the execution layer. A page can look fine to a human and still fail for an automated visitor if the form, call to action, rendering path, or confirmation step is not accessible enough for the agent to complete the task.
Where, Exactly, Would An LLM Even Use Schema?
There are two camps in the LLM/schema debate, and most arguments collapse into one of them. Camp 1: Schema is hoovered up during the training of the model and ends up "baked in" somehow. Camp 2: Schema is read at the moment the LLM. The practical question is what this changes in the system: the page structure, the evidence presented, the measurement habit, or the way the topic is connected to related work.
The practical value is in connecting the idea to an observable signal. That means deciding what should be checked, what would prove the issue is real, and where the team should make the smallest useful improvement first.
Camp 1: Schema Gets Into Training Data
I have written about this before, and it was covered by Search Engine Roundtable last year. The short version is that this is the most popular theory and also the one with the weakest mechanical case behind it. There are two problems, and. The search implication is whether the section improves the evidence around the page, not simply whether it adds more wording. Clear entities, crawlable structure, internal links, and useful context are what make the topic easier to evaluate.
The useful check is whether this improves the system behind search performance, not only the words on the page. Internal links, crawlable content, clear entities, current evidence, and a sensible page structure all help the recommendation become easier to trust.
Problem 1: Schema Is Almost Certainly Stripped Before Training
If you have not gone down the rabbit hole of how base LLMs are actually made, Andrej Karpathy's three and a half hour deep dive on LLM pre training is the canonical reference, and yes, three and a half hours is the deal. Pre training. The practical question is what this changes in the system: the page structure, the evidence presented, the measurement habit, or the way the topic is connected to related work.
Problem 2: Even If It Survived, It Would Not Work The Way You Think
Let's be generous and stipulate that some non trivial amount of raw schema does sneak into a model's training data. We do not actually have full transparency from Frontier Labs about what they ingest, and the courts have not exactly been. The practical question is what this changes in the system: the page structure, the evidence presented, the measurement habit, or the way the topic is connected to related work.
Camp 2: Schema Gets Read At Query Time
I've experienced that it is rare for any LLM/schema proponents to want to discuss training data involvement once it has been gently set on fire. The argument tends to move quickly onto the possibility that schema is not in the model. The practical question is what this changes in the system: the page structure, the evidence presented, the measurement habit, or the way the topic is connected to related work.
Flavor 1: "Schema Feeds The Knowledge Graph"
Google's Knowledge Graph is a vast, curated, slow moving database of entities and relationships. It is fed by structured data, Wikipedia, Wikidata, freebase legacy data, and a hundred other signals. It is built and updated by Google's. The practical question is what this changes in the system: the page structure, the evidence presented, the measurement habit, or the way the topic is connected to related work. This connects with to Identify and Prioritize Entity Gaps when the same signal needs a clearer operating decision.
Flavor 2: "Microsoft Confirmed Schema Feeds Copilot"
Misquoted to an industrial scale, Search Engine Land's write up ran under the headline "Microsoft Bing/Copilot use schema for its LLMs," in which Fabrice Canel of Microsoft was reported to have "confirmed" that schema markup helps. The measurement question is whether this signal changes a decision, not whether it adds another number to a dashboard. Useful reporting connects visibility, engagement, and business outcomes without pretending every AI influenced journey will produce a clean click path.
The reporting question is whether this signal changes a decision. If it only creates another number in a dashboard, it adds noise. If it helps separate profile activity, website visits, calls, bookings, and direction requests, it can make local performance easier to understand.
Flavor 3: "LLMs Return Information That Was Only In The Schema, Therefore They Use Schema"
This is the one that prompted the experiment. It is also the single most cited piece of "evidence" in GEO LinkedIn posts, and the most easily falsified once you spend half an afternoon thinking about it. I built a deliberately silly test. The search implication is whether the section improves the evidence around the page, not simply whether it adds more wording. Clear entities, crawlable structure, internal links, and useful context are what make the topic easier to evaluate.
Conjecture: Could LLMs Be Using Schema, Somehow, Somewhere?
The honest answer is that we do not know what is happening upstream at OpenAI, Anthropic, Google DeepMind, xAI, and the rest, because they are not telling. Google itself is a sprawl of separate systems (the index, re rankers, glue, the. The practical question is what this changes in the system: the page structure, the evidence presented, the measurement habit, or the way the topic is connected to related work.
What the visibility signal actually changes
What the visibility signal actually changes: schema, LLMs & the Low Bar for ‘Evidence’ in GEO: the Practical Angle should be treated as a visibility signal, not a standalone headline. Introduction TL;DR: I ran a small experiment to try and get some insight into whether large language models actually parse schema markup or are just nodding politely in its direction. I put a fake company address (inside beautifully invalid JSON LD, on a page. The same pattern also shows up in Not Effort, where the practical question is how the signal becomes visible.
What the visibility signal actually changes: the practical question is whether the page, brand evidence, and surrounding content make the answer easier to trust. If that support is weak, search systems can still understand the topic but fail to connect it confidently to the brand.
What the visibility signal actually changes: that is why the response should begin with an audit of the evidence already on the site before creating a new asset. The fastest improvement is often a clearer page, a better internal link, or a stronger explanation of why the brand belongs in the answer.
Comments
Comments are published automatically. Links are not allowed inside comments.