What Co Mentions Reveal About AI Recommendation Gaps
/ 6 min read

Summary
For this case study, we tested 12 athleisure and activewear brands across ChatGPT, Gemini, Perplexity, Claude, and Google AI. The practical question is what this changes for SEO, content quality, and AI search visibility.

We've spent the last two years optimizing for AI visibility by focusing on what we say about ourselves: writing better About pages, adding clear schema and SameAs markup, structuring content more effectively, and providing more direct answers. All of these principles still apply and are essential for the qualification phase of an LLM's brand processing (clarity + relevance).
But a study João da Silva and I conducted using Friction AI's platform puts a number on a factor the industry has been circling around but couldn't prove. Among brands that were already recognized (where the LLM could describe them accurately), Knowledge Graph (KG) strength predicted visibility within the category each brand was coded to. What it didn't predict was whether a brand would surface in an adjacent category query, even if it belonged there from a business perspective. The same pattern also shows up in New Study Finds 4 Key SEO Insights, where the practical question is how the signal becomes visible.
What brands did we test and how did we test them?
For this case study, we tested 12 athleisure and activewear brands across ChatGPT, Gemini, Perplexity, Claude, and Google AI Overviews: 14,140 API runs over seven days, using UK geography with web search enabled. For each brand, we ran two types of prompts: Recognition prompts ("What is [Brand]?" and "Describe [Brand]") Recommendation prompts ("Best athleisure brands," "Top 10 athleisure brands," and "Which athletic apparel brands are worth buying in 2026?") The brands spanned three Knowledge Graph tiers, assigned by Google KG resultScore (the raw score returned by Google's Knowledge Graph Search API, a proxy for how strongly an entity is established in Google's index), so we could test whether KG strength predicted recommendation visibility: Low KG: LNDR, TALA, Gymshark, Varley. Mid KG: Reebok, Outdoor Voices, Rhone Apparel, Sweaty Betty. This connects with AI Recommendation Sets Leave Some Brands Out when the same signal needs a clearer operating decision.
High KG: Alo Yoga, Nike, lululemon, New Balance. Spoiler ahead: The high KG brands didn't dominate recommendations. The mid KG tier showed the largest average gap between recognition and recommendation.
What brands did we test and how did we test them? is where brand work becomes machine readable. Consistent third party evidence, clear entities, credible pages, and a stable narrative help search systems understand what the brand should be trusted for.
Recommendations: What the co mention data showed
We mapped how often brands appeared together in athleisure content across external sources (articles, reviews, comparison pieces, and editorial lists) crawled via API from UK indexed sources. Some of the most interesting results include: lululemon + Alo Yoga: 534 co mentions. Gymshark + lululemon: 264 co mentions.
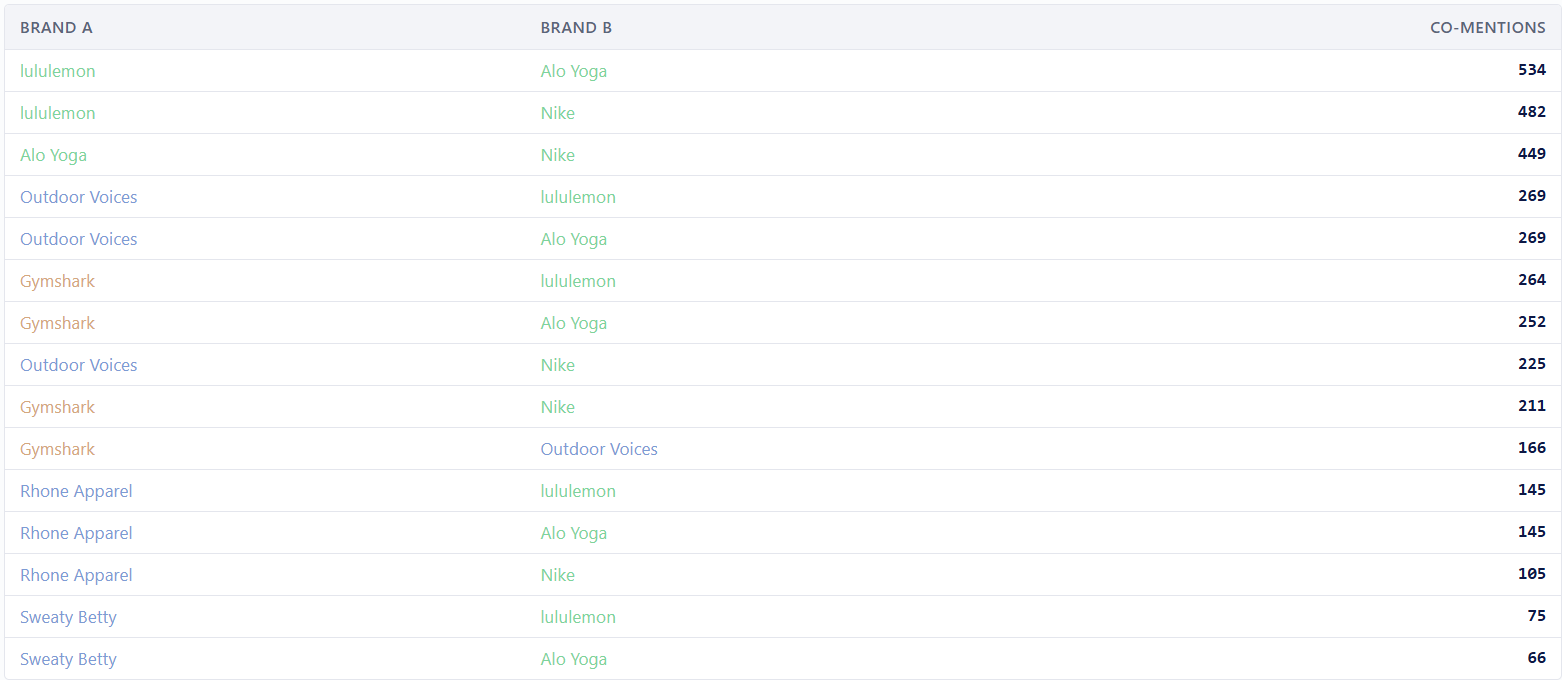
Gymshark + Alo Yoga: 252 co mentions. These brands appear together repeatedly in the same articles, roundups, and editorial comparisons across independent sources. Together, they form a cluster that the LLM treats as "athleisure." Now look at the other end of the spectrum.
Recommendations: What the co mention data showed is really about permission and control. Publishers are trying to separate ordinary discovery from dataset extraction, and that distinction is becoming harder to ignore as AI systems depend on large public web archives. A useful companion note is Questions That Reveal Your Real Search Performance, because it looks at a nearby part of the same system.
Nike, the hero: Same KG description, completely different results
Nike, New Balance, and Reebok share the same KG entity description: "Footwear company." LLM probing across all five systems assigns all three unanimously to the athletic_footwear category, so from a pure entity clarity standpoint, they start from the same position. However, their recommendation rates in athleisure queries aren't remotely equivalent. Nike surfaces in 71% of athleisure recommendation prompts, while New Balance and Reebok appear in 0% across all five LLMs and all 14,140 runs.
The difference isn't how they're defined ("Footwear company"). It's which conversations they appear in and which other brands appear alongside them. LLMs don't infer category adjacency.
The third party citation weight in recommendation vs. recognition data
When we split citations by prompt type, recognition vs recommendation, a pattern emerges that should reframe where most GEO budgets are being spent. For recognition prompts, where the user has already typed your brand name, own brand content is the dominant source: ChatGPT cited own brand content 49% of the time. This is where your About page and homepage are used for clarity, and your services, category, and guide pages are used for relevance.

Recommendation prompts give us completely different results. When the user hasn't named your brand and is asking for the best option in a category, own brand citations drop to 18% on ChatGPT and to effectively zero on Gemini, Claude, Perplexity, and Google AI Overviews. Third party sources account for 82% to 100% of what gets cited across all five systems.
The third party citation weight in recommendation vs. recognition data shows why AI search is becoming a budget and measurement problem, not only a visibility topic. Teams need to keep SEO fundamentals working while building a clearer view of assisted demand, attribution gaps, and revenue impact.
What the co mention structure means for PR and content strategy
As we've seen so far, being mentioned in a category isn't enough. Being mentioned alongside the right brands in a category is what places you in the concept graph for that cluster. A press mention that describes a brand as "performance apparel" in isolation does little to advance its athleisure concept graph placement.
A press mention that lists it alongside lululemon, Alo Yoga, and Gymshark in an editorial comparison does considerably more because it builds the co occurrence signal the model needs to associate the brand with that cluster. The same logic applies across content type.
Editorial roundups and comparison pieces
Being included in "best of" lists that name your category competitors is worth more to your concept graph than a standalone brand profile. The cluster signal comes from appearing in the same article as the brands that define the category.
Podcast appearances
If the host introduces you in relation to specific named brands, or compares your approach to a category leader, that co occurrence gets indexed. A bio that says "founder of [Brand], which competes with lululemon and Gymshark in the premium athleisure space" does different work than a bio that says "founder of [Brand], a performance apparel company."
Analyst and industry reports
Category level reports that group brands together are high signal co mention sources. Being included in a sector analysis alongside your category peers places you in the concept graph in a way that standalone coverage doesn't.
Retailer and comparison taxonomy
Being stocked and categorized alongside category leaders in a major retailer's taxonomy is a co mention signal. The retailer's category page is external content that places your brand in a cluster. The goal is visibility in the right company.
Track, optimize, and win in Google and AI search from one platform.
A note on the data and what comes next
This study covers a single category, athleisure and activewear, with 12 brands tested in the UK. The co mention figures are raw co occurrence counts from UK indexed sources crawled via API, covering content indexed at the time of the study in May 2026. Cross category validation and additional geography testing are in progress.
The full paper, " The Recognition Recommendation Gap: Empirical Evidence That Category Coding, Not Knowledge Graph Strength, Determines Brand Visibility in Generative AI Output," has been published by João da Silva and me on Zenodo and documents the methodology, brand sample, prompt set, and extraction code in sufficient detail for independent replication. But the pattern in the co mention data is clear enough to act on now. Three brands share the same Knowledge Graph description: one appears in 71% of athleisure recommendation responses, and two appear in 0%.
Comments
Comments are published automatically. Links are not allowed inside comments.