Brand Depth Determines What AI Systems Recommend
/ 9 min read

Summary
Each layer influences visibility differently. The practical question is what this changes for SEO, content quality, and AI search visibility.

Introduction
The key issue here is Getting cited in AI answers is becoming a common visibility metric. But citations alone don't explain why certain brands consistently appear in ChatGPT, Google AI Mode, Perplexity, and other AI search systems. Citations reflect visibility outcomes, not the. My read is to treat it as a decision point: what signal needs to become clearer, what part of the system is currently weak, and what evidence would show that the work is improving visibility rather than only adding activity. This connects with AI Recommendation Sets Leave Some Brands Out when the same signal needs a clearer operating decision. The same pattern also shows up in Proven Strategies to Get Your Brand Cited, where the practical question is how the signal becomes visible.
That is the difference between reacting to a trend and building a useful search system. Connect this point back to the page template, internal linking, entity signals, content depth, crawl accessibility, and the way the brand is represented across the wider web before deciding what to change first.
Most of us have started tracking how often our brands are cited in AI answers. It feels like the new gold standard for visibility. But if you only look at citations, you are looking at the receipt rather than the transaction. A citation is an outcome, not the cause.
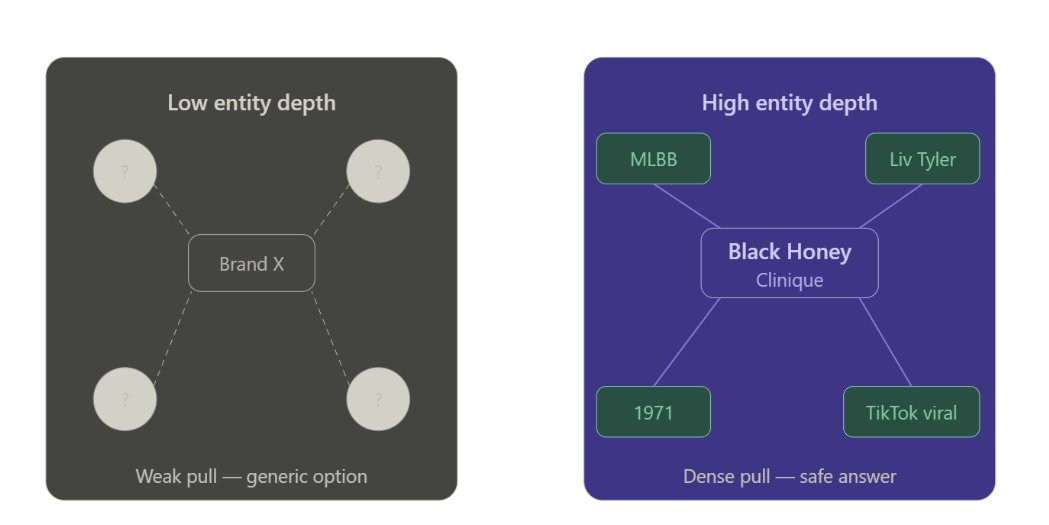
AI systems do not pick brands at random or based solely on a few good links. They prioritize brands that have a deep semantic presence across the entire web, including training data, media coverage, and interconnected entities. If you want to be recommended, you have to move beyond simple optimization and start building brand depth.
The two games of generative engine optimization
When we talk about Generative Engine Optimization, or GEO, we are actually dealing with two distinct challenges. One is a long term play regarding how the model perceives you, and the other is a technical play regarding how your content survives a live search.
Game 1: Parametric weight
Think of a brand as a set of coordinates in the embedding space of a Large Language Model. This position is defined by how dense and consistent the signals are within the training data. This is what we call parametric weight.
You cannot build this overnight. It is the result of months or years of consistent presence across the web. When your messaging is fragmented or inconsistent, your brand vector becomes fuzzy. This makes the model less confident in recalling your brand, which often makes you feel interchangeable or forgettable.
The tricky part is that you cannot simply edit what a model has already internalized. You are essentially playing for the next training cycle. If you spend all your time chasing citations without building this foundation, you are ignoring the structural weight that makes citations inevitable.
Expert Interpretation: The tradeoff here is between immediate visibility and long term authority. Many marketers want a quick win, but parametric weight is a slow burn. The decision you need to inspect is whether your current brand messaging is consistent enough across the web to create a sharp, clear vector, or if you are sending conflicting signals that confuse the model.
Game 2: Retrieval survival
While parametric weight is about what the model knows, retrieval survival is about what the model finds in the moment. When a system like ChatGPT Search or Google AI Mode triggers a retrieval pipeline, your content has to survive a brutal filtering process.
Interestingly, about 85 percent of brand mentions in AI search come from external domains rather than the brand's own website. Each system handles this differently. Perplexity, for example, retrieves and ranks citations before the LLM even begins to generate a response. Google AI Mode uses a process called query fan out, where it breaks a single query into 8 to 12 parallel subqueries across the live web and the Knowledge Graph. A useful companion note is Paid Brand Mention Problem in GEO, because it looks at a nearby part of the same system.
ChatGPT Search takes a different path, expanding a query into several semantic variations and retrieving between 35 and 42 candidate URLs, only to disqualify 83 percent of them before the final synthesis.
Expert Interpretation: This highlights a massive dependency on third party validation. If your brand only exists on your own domain, you are fighting an uphill battle. The decision to inspect here is your external footprint. You must ask if the external sites talking about you are high quality enough to survive these aggressive retrieval filters.
Citations are receipts
There is a surprising gap between being mentioned and being cited. Data shows that only 6 to 27 percent of brands that are frequently mentioned are also top cited sources. This means a model can know exactly who you are and recommend you without ever providing a link to your site.
If you optimize only for the citation, you are optimizing for the receipt. Brand depth, created through consistency and cross source coverage, is what makes your brand the statistically low risk answer before the system even decides whether to cite you.
Expert Interpretation: This is a critical distinction because it separates brand awareness from lead generation. You can have high recommendation rates but low citation rates. The tradeoff is that while citations drive traffic, the recommendation itself drives the mental shift in the user. You should inspect whether you are chasing the link or the recommendation.
How LLMs and humans default to the familiar
AI models operate in a way that is remarkably similar to the human brain. We both rely on mental frameworks and heuristics to avoid the exhaustion of making a million new decisions every day.
This is rooted in predictive processing theory. The brain acts as a forecasting engine, using past information to minimize errors and ambiguity. LLMs do the same. When faced with a query, both human cognition and AI prioritize the information that is most densely established. They default to the familiar because it is the safest bet.
Expert Interpretation: This means that being the best is often less important than being the most familiar in a semantic sense. The risk is that a mediocre brand with high depth will beat a superior brand with low depth. To compete, you must increase your semantic density to reduce the perceived risk for the AI.
The technical components of brand depth
AI models and Google's Knowledge Graph often drink from the same well of trusted websites. While the LLM looks for words that frequently appear together, Google builds a network of connected facts. To understand brand depth, we have to look at three specific metrics.
Entity salience
Salience is about how prominent and distinct your brand is within a specific topic cluster. When a user asks a question about a topic, the AI asks which entities have enough statistical weight to surface.
If you have low salience, you only appear when someone searches for your brand name specifically. High salience means you appear when the topic is discussed, regardless of whether your name was mentioned in the query. Google uses systems like RepositoryWebrefLatentEntities to map these relationships.
Expert Interpretation: Salience is the difference between being a known brand and being a category leader. The decision to inspect here is your topical association. Are you tied to a broad category, or are you just a name in a vacuum?
Entity coherence
Coherence is the consistency of your identity across all retrieved contexts. If your naming is inconsistent, your positioning conflicts, or your dates are contradictory, you signal to the AI that you are unreliable.
When an LLM encounters this incoherence, it creates a fragmented representation of your brand. This leads to brand drift, where the AI's version of your company slowly diverges from reality because there was no stable anchor to hold it in place.
Expert Interpretation: Coherence is an infrastructure problem. The tradeoff is between the flexibility of evolving your brand and the stability required by AI. You must inspect your digital footprint for contradictory information that might be triggering this drift.
Inter entity relationship density
This is the strength and number of connections between your brand and other authoritative entities, such as specific products, concepts, or proofs. This density determines your associative retrieval paths.
In agentic systems like Perplexity Pro or Deep Research, the AI takes multiple reasoning steps. Relationship density determines if you survive the second or third hop. If your brand only exists at the center of its own graph, you disappear the moment the query moves one step sideways.
Expert Interpretation: This is where most brands fail. They build a silo instead of a web. The decision to inspect is your connection to other authoritative entities. If you are not linked to the concepts and people that define your industry, you are invisible to agentic AI.
The RAG layer as a quality gate
Retrieval Augmented Generation, or RAG, is where site quality becomes a hard gate. There is evidence of a site quality score on a scale from 0 to 1. Sites that score below roughly 0.4 are simply not retrieved as candidates.
This means that no amount of keyword optimization can save you if your site quality is too low. Brand integrity is not just about marketing, it is about infrastructure. You cannot optimize your way into a citation if you have not first built the coherence and relationship density that makes you retrievable.
Expert Interpretation: This creates a binary outcome: you are either in the pool or you are not. The tradeoff is that high quality takes more time to build than high volume. You should inspect your technical site health and content depth to ensure you are above that 0.4 threshold.
Case study: The semantic depth of Black Honey
Clinique's Black Honey lipstick provides a perfect example of how co occurrences create recommendation loops. The brand does not just exist as a product, it exists as a dense cluster of associations.
Concepts: It co occurs with phrases like universally flattering and my lips but better. Trends: It is tied to TikTok virality from 2021. Competitors: It is frequently mentioned alongside the e.l.f. Black Cherry dupe, which reinforces its status as the benchmark. Cultural Anchors: It is linked to Liv Tyler and the character Arwen. History: It is tied to the year 1971, proving longevity.
Because of this density, the AI sees it as a low risk, high confidence answer.
Expert Interpretation: The lesson here is that you should not just describe your product, you should anchor it to existing cultural and technical entities. The decision to inspect is your own co occurrence map. What other entities should the AI associate with you to increase your confidence score?
Strategies for retrieval and recommendation
To be recommended, you must build for the layer that determines synthesis weight. This means focusing on what actually survives the retrieval funnel.
Prioritize high density content
Generic and predictable content is often skipped because the LLM can generate that information on its own. To be retrieved and cited, you need specific, data rich content that is hard to reproduce.
This means adding high density assets like detailed company histories, team bios, and ISO certifications. These serve as grounding data for RAG systems, providing the quantitative values and specific entities that a model cannot plausibly invent.
Comments
Comments are published automatically. Links are not allowed inside comments.