Reasoning Lift: What Happens to Brand Visibility When AI Thinks Harder
/ 7 min read

Summary
Data comes from the Semrush AI Visibility Toolkit, which captures the prompts, citations, and fan out queries ChatGPT generates. The practical question is what this changes for SEO, content quality, and AI search visibility.

For a long time, we've treated LLMs as single mode engines. You put in a prompt, and you get an answer. But as models evolve, we're seeing a divergence in how they actually process information. Some responses are "fast", relying on internal weights and memory, while others are "slow," utilizing a reasoning process that involves deeper research and more extensive web grounding.
This distinction isn't just a technical curiosity; it fundamentally changes which brands get mentioned and why. If the AI "thinks" harder, it doesn't just give a better answer, it often looks at a completely different part of the internet to find that answer. For anyone managing a brand's digital presence, understanding this "reasoning lift" is the difference between being visible to a casual user and being the recommended solution for a high intent buyer. The same pattern also shows up in to Improve Your Brand’s LLM Visibility, where the practical question is how the signal becomes visible.
The framework for measuring AI reasoning
To understand this shift, it's necessary to move beyond single query testing. The reality of AI usage is conversational; users don't just ask one question, they move through a journey. To capture this, data was gathered using the Semrush AI Visibility Toolkit, focusing on how ChatGPT 5.2 behaves across different reasoning modes.
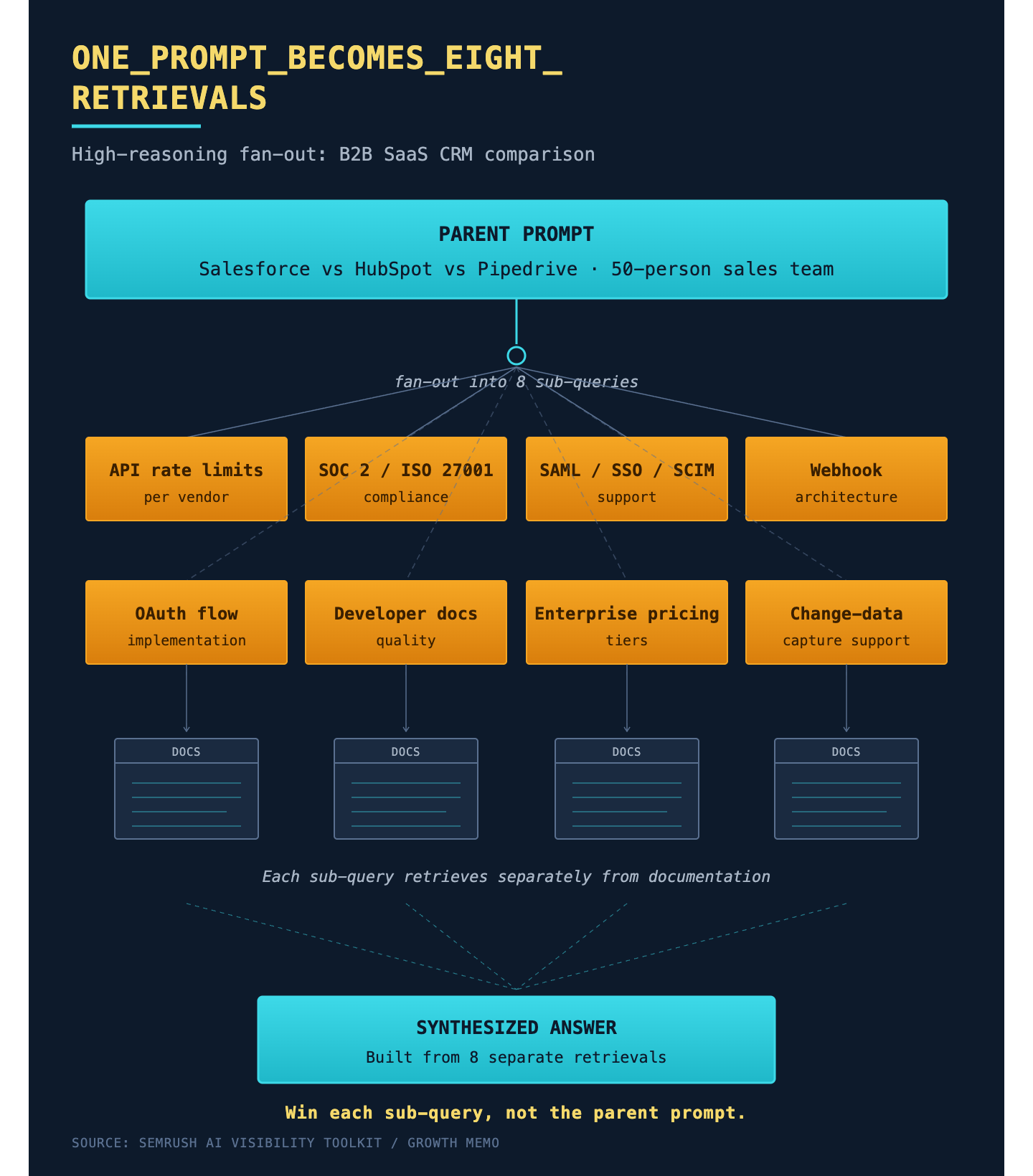
The study tracked 20 distinct buyer journeys across four key sectors: Finance, Consumer Tech, B2B SaaS, and Health/Lifestyle. Each journey was broken down into five logical stages that mirror how humans actually make decisions:
Problem: Identifying the need (e.g., "Do I even need a CRM?"). Exploration: Understanding the landscape (e.g., "What types of CRMs exist?"). Comparison: Weighing specific options (e.g., "HubSpot vs. Salesforce"). Validation: Confirming the choice (e.g., "Is this worth the price for my size?"). Selection: Final execution (e.g., "How do I start with this tool?").
By running 100 prompts twice, once with minimal reasoning and once with high reasoning, the analysis could isolate exactly how the model's "thought process" changes its reliance on external citations and the specific domains it chooses to trust.
Expert Interpretation: Most AI tracking today is "flat", it measures a single prompt and a single response. However, the real value is in the sequence. By mapping AI visibility to a five stage funnel, we can see where a brand is "leaking" visibility. The tradeoff here is complexity; it is much harder to track a 5-step journey than a single keyword, but it's the only way to see if your brand has actual persistence in a conversation.
The quantitative gap: More search, more sources
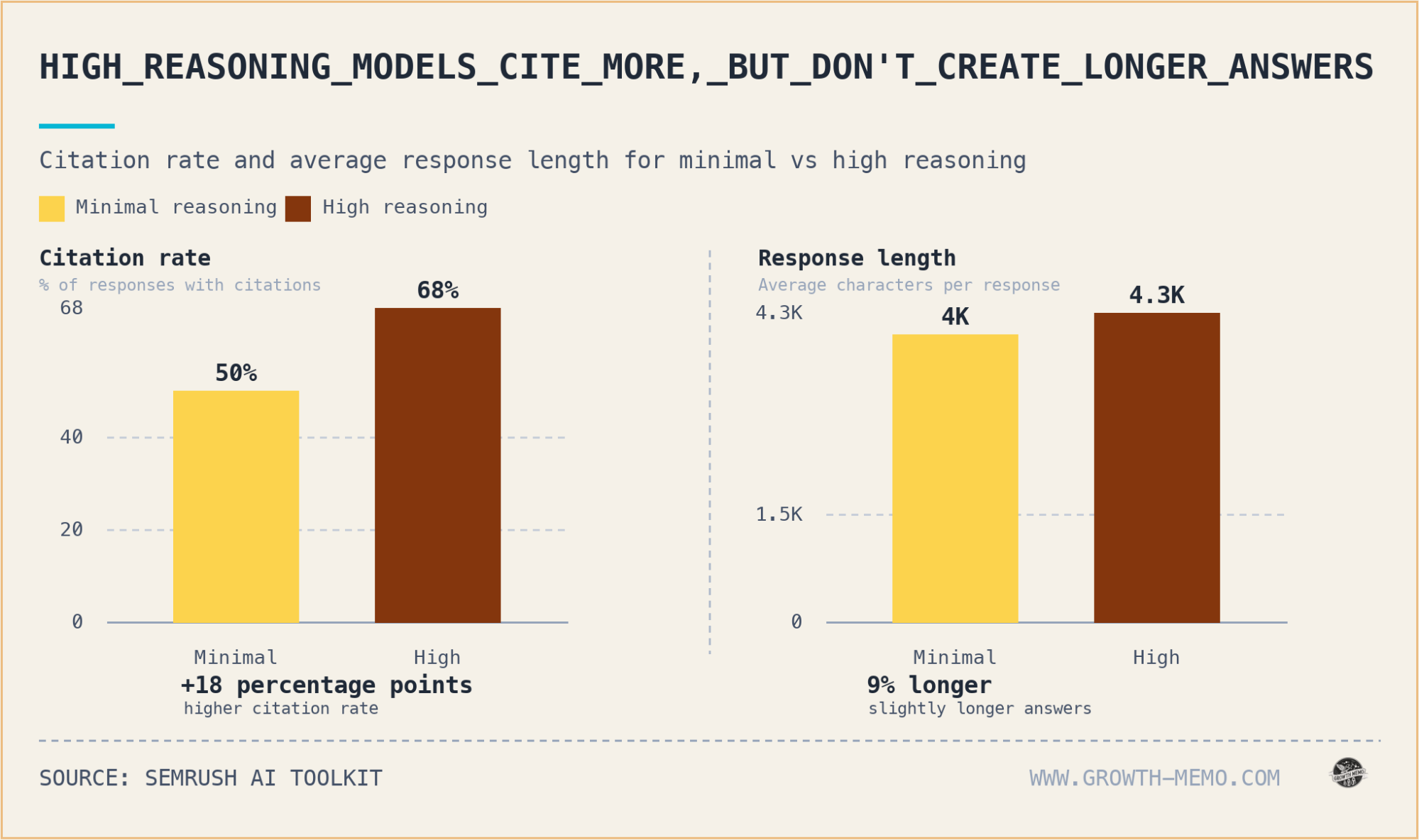
When high reasoning is activated, the model's behavior shifts from "recalling" to "researching." The data shows a significant jump in grounding. The citation rate, the frequency with which the AI cites at least one external source, climbs from 50% in minimal mode to 68% in high reasoning mode.
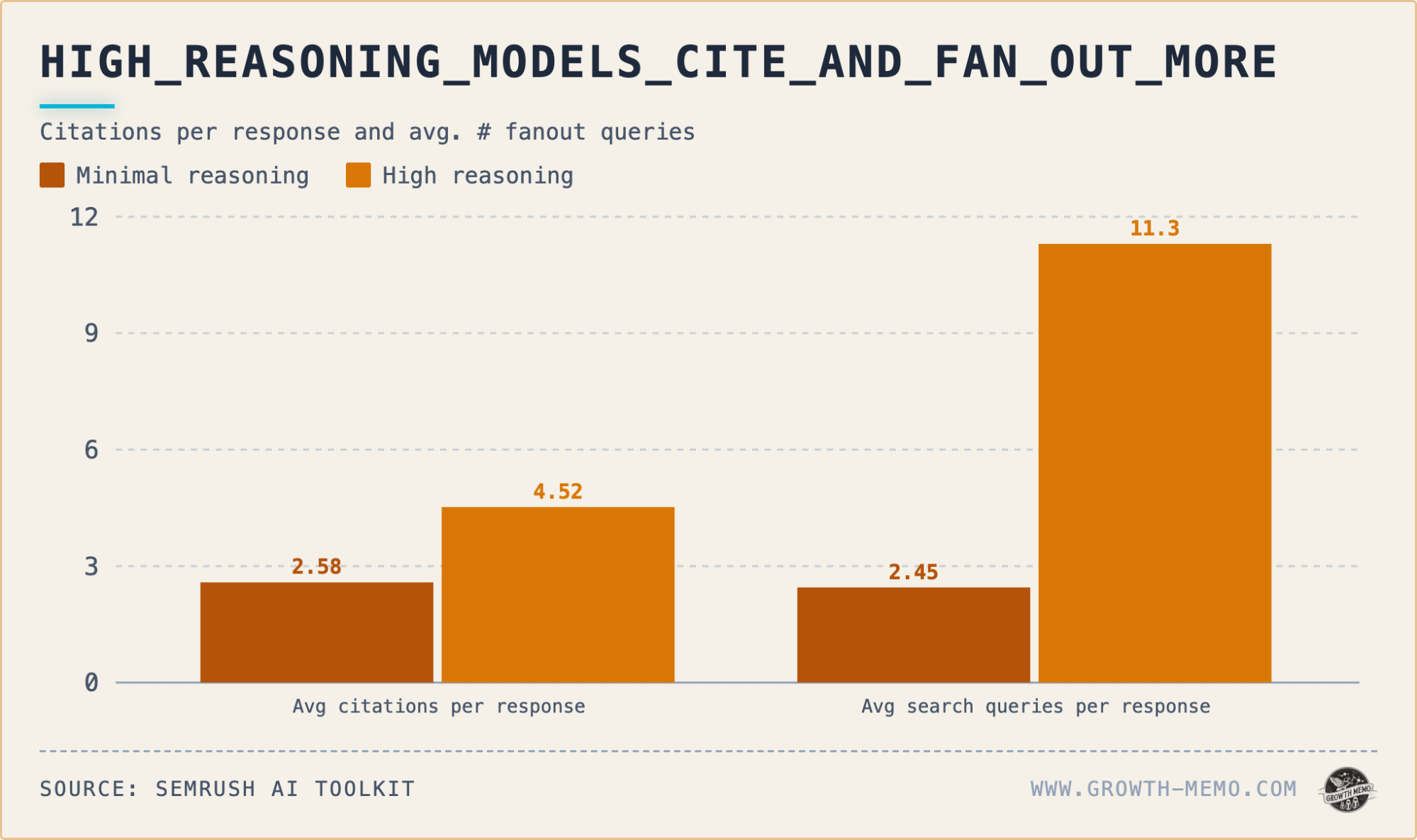
It isn't just that the AI cites more often; it cites more deeply. The average number of sources per response nearly doubles, moving from 2.6 to 4.5. Even more striking is the "fan out" activity, the internal sub queries the AI fires to gather information before finalizing its answer. These queries increase by 4.6x when high reasoning is engaged.
Perhaps the most critical finding for brand owners is the domain diversity. High reasoning pulled from 173 unique domains, compared to just 127 for minimal reasoning. Crucially, 99 of the domains cited in high reasoning mode never appeared once in the minimal reasoning results. This suggests that "thinking harder" leads the AI to a nearly different version of the web.
It is also important to note that users don't always manually toggle this mode. AI systems often auto route complex prompts, such as those involving regulatory compliance, multi criteria comparisons, or intricate shopping frameworks, into "Thinking" mode automatically. This means your visibility depends less on the user's subscription tier and more on the complexity of the query.
Expert Interpretation: This reveals a massive blind spot in traditional SEO. If you are only optimizing for the "fast" answers, you are invisible to the AI when it enters "research mode." The decision to inspect here is your content's complexity. If your content only provides surface level answers, you'll likely only appear in minimal reasoning responses. To capture the high reasoning lift, you need to provide the depth and data that a "thinking" model requires to justify a citation.
How reasoning scales across the buyer journey
The difference between minimal and high reasoning isn't a flat line; it fluctuates based on where the user is in their decision making process. The model treats different stages of the funnel with different levels of intensity.
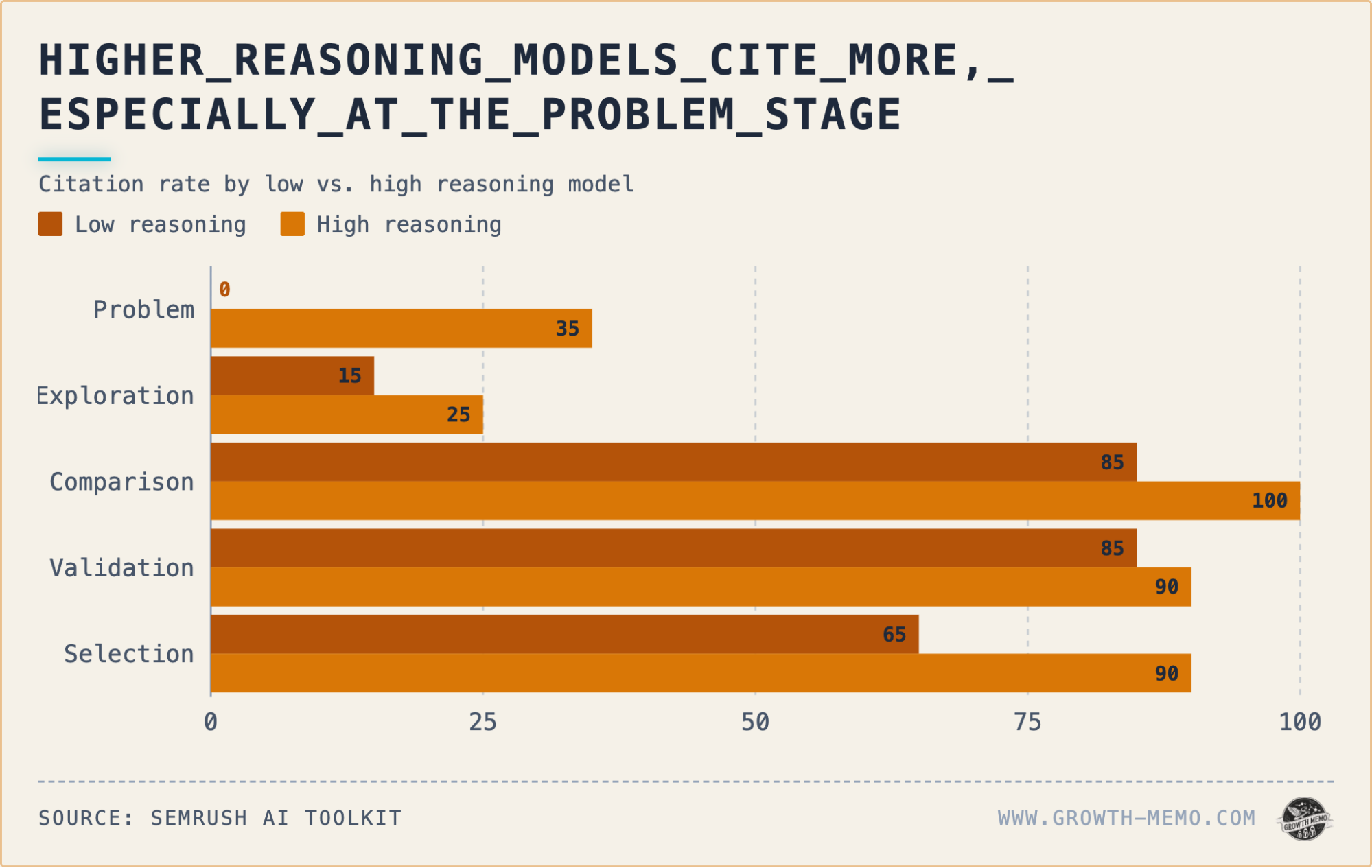
In the early "Problem" stage, the gap is most aggressive. High reasoning increases the citation rate by 35 percentage points compared to minimal reasoning. In this phase, minimal reasoning tends to answer from internal memory, while high reasoning treats the query as a research task, actively seeking out external validation.
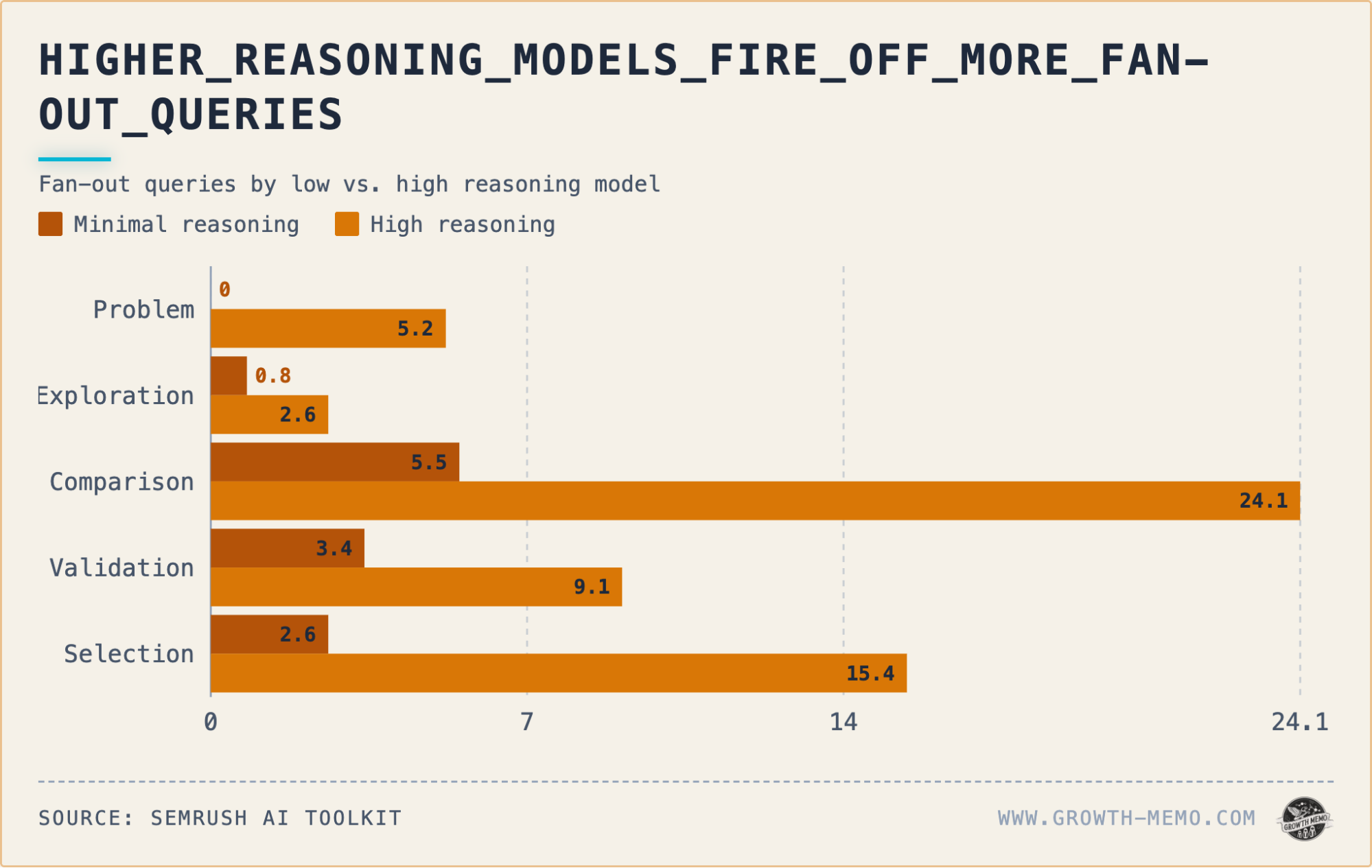
As the user moves deeper into the funnel, the gap narrows. By the "Validation" stage, the difference in citation rates is only about 5 percentage points. However, the intensity of the research peaks during the "Comparison" stage. Here, high reasoning fires an average of 24 sub queries per response, while minimal reasoning only fires 5.5. The number of citations also peaks here, with high reasoning averaging 9.8 sources per response versus 5.8 for minimal.
This creates an "hourglass" effect. The AI starts with heavy research in the problem phase, expands into massive data gathering during comparison, and then narrows down as the user reaches the selection phase.
Expert Interpretation: This tells us that the "top of the funnel" (TOFU) is not dead in the AI era, it's just changed. Because high reasoning AI treats early stage questions as research tasks, there is a renewed opportunity for educational, problem centric content to gain visibility. The tradeoff is that you are competing in a much more crowded research environment. You should inspect whether your TOFU content is designed to be "cite able" as a factual resource, rather than just a lead gen magnet.
The compounding effect of brand persistence
The most significant strategic insight is how reasoning affects brand continuity. In a conversational interface, the goal isn't just to be mentioned once, but to remain the preferred option as the conversation evolves from a general problem to a specific purchase.
When using minimal reasoning, brand persistence is non existent. Zero journeys showed a brand being cited in the first stage (Problem) and maintaining that visibility all the way through to the final stage (Selection). In minimal mode, every stage of the journey is essentially a fresh fight for visibility.
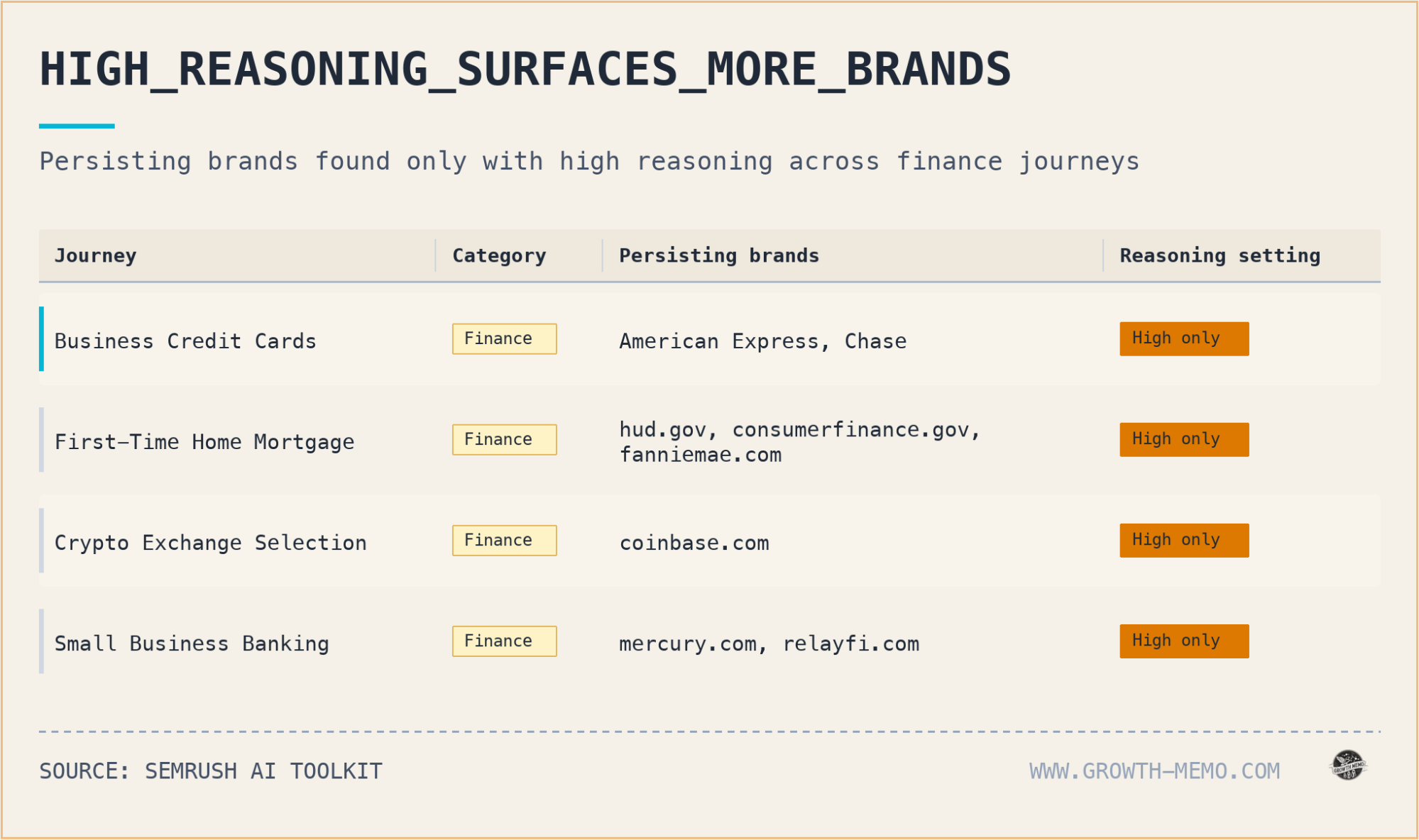
High reasoning changes this dynamic entirely. In several journeys, brands cited at the start persisted through all five stages. high reasoning tends to "anchor" more heavily on its chosen sources. In over half of the high reasoning responses, the model cited the same source multiple times within a single response, showing a higher level of trust and reliance on specific data points. This connects with AI Recommendation Sets Leave Some Brands Out when the same signal needs a clearer operating decision.
Expert Interpretation: This is the "compounding interest" of AI visibility. If you can win the citation in the "Problem" or "Exploration" phase under a high reasoning mode, you have a significantly higher chance of staying in the conversation until the "Selection" phase. The decision here is to stop viewing AI mentions as isolated events and start viewing them as a chain. If you are appearing in the "Comparison" stage but not the "Problem" stage, you are missing the chance to anchor the user's preference early.
Treating reasoning modes as separate search engines
The data leads to a stark conclusion: minimal reasoning and high reasoning are not just different settings, they are effectively two different search engines. Three out of four domains cited in one mode are not cited in the other. They pull from different sources, appear at different stages of the funnel, and exhibit different behaviors regarding brand persistence.
This means that aggregating your AI visibility data is misleading. If you average your "share of voice" across all responses, you are blending two entirely different systems, which masks the reality of how your brand is performing. A useful companion note is search visibility, because it looks at a nearby part of the same system.
To get an accurate picture, prompt tracking must be split by reasoning mode. While this increases the cost and effort of monitoring, it removes the noise. It allows a brand to see if they are winning the "fast" answers (memory based) or the "slow" answers (research based).
Expert Interpretation: The biggest risk here is "averaging to mediocrity." If you see a 20% visibility rate, you don't know if you're dominating the high intent reasoning queries or just appearing in a few low value minimal responses. The tradeoff is a higher operational burden for your SEO or marketing team, but the reward is a precise map of where you stand in the AI driven buyer journey. You must decide if you are optimizing for the "quick answer" or the "deep research" user, as the content requirements for each are fundamentally different.
Comments
Comments are published automatically. Links are not allowed inside comments.