Understanding AI Crawlers and the Access Decisions They Force
/ 6 min read

Summary
A practical view on Understanding AI Crawlers and the Access Decisions They Force, focused on the signal to inspect, the risk to avoid, and the decision it should change.

The Hidden Workforce Behind Digital Visibility

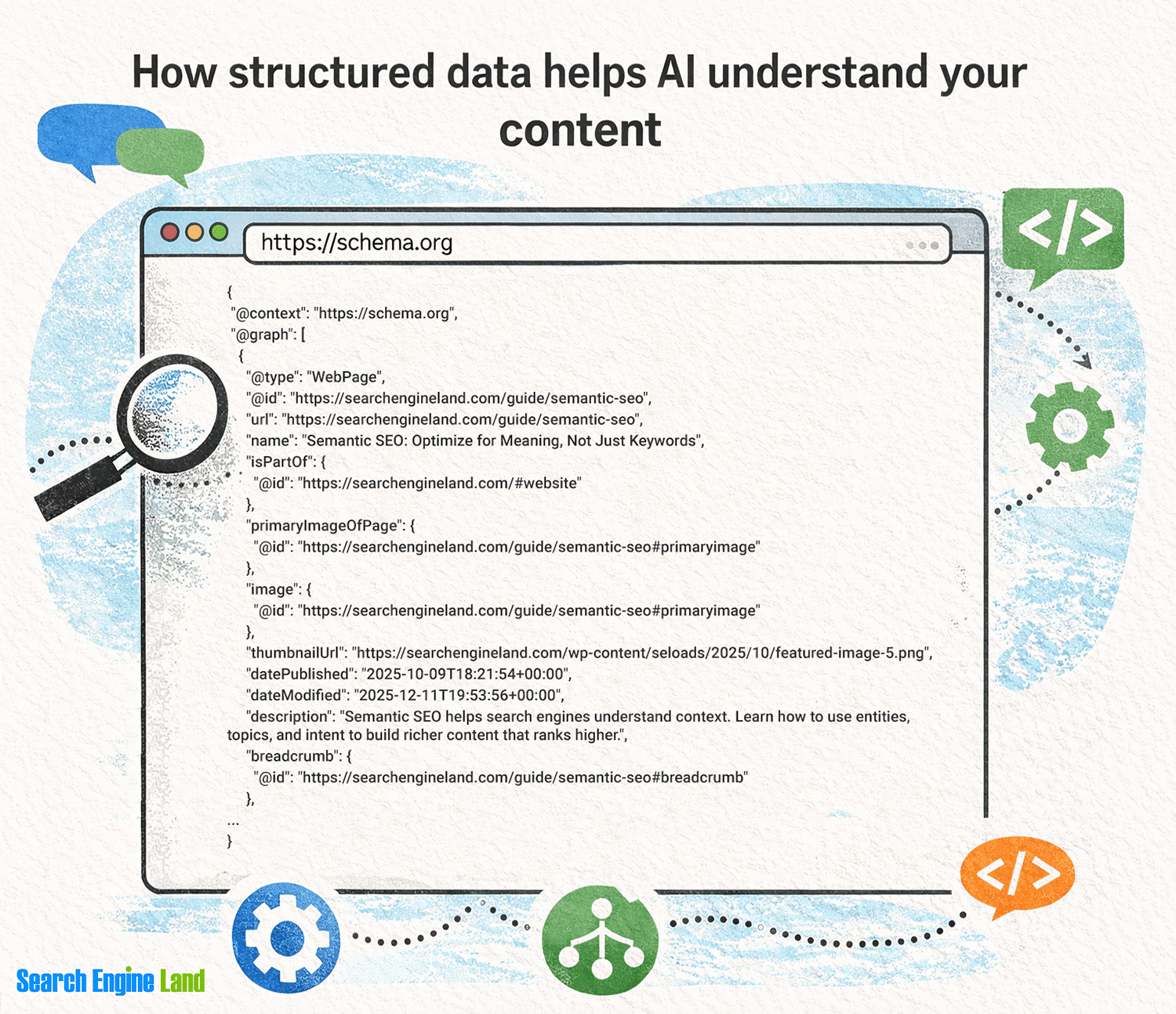
What Do AI Crawlers Do and Why Are They Important?
Do AI Tools Crawl Websites or Rely on LLMs?
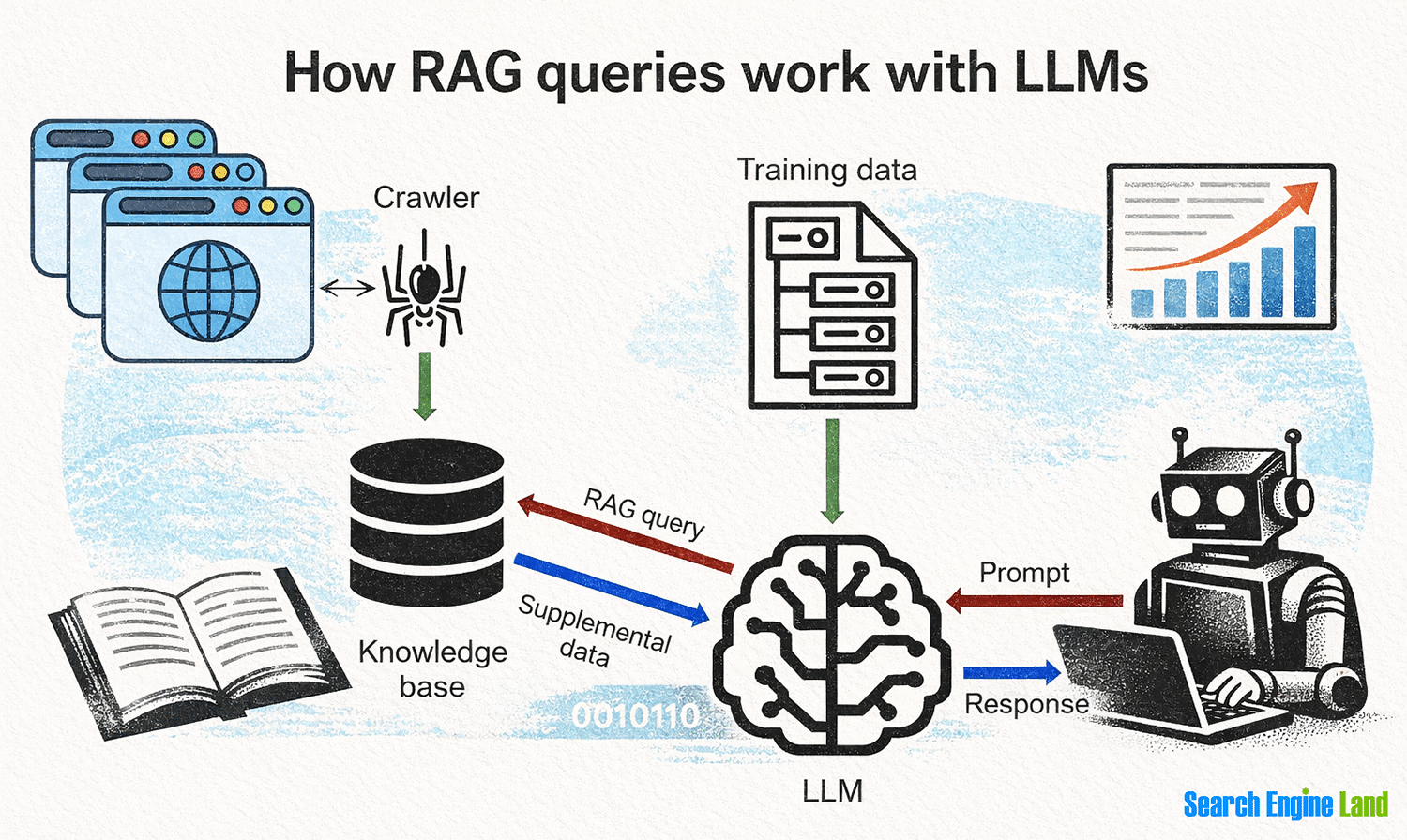
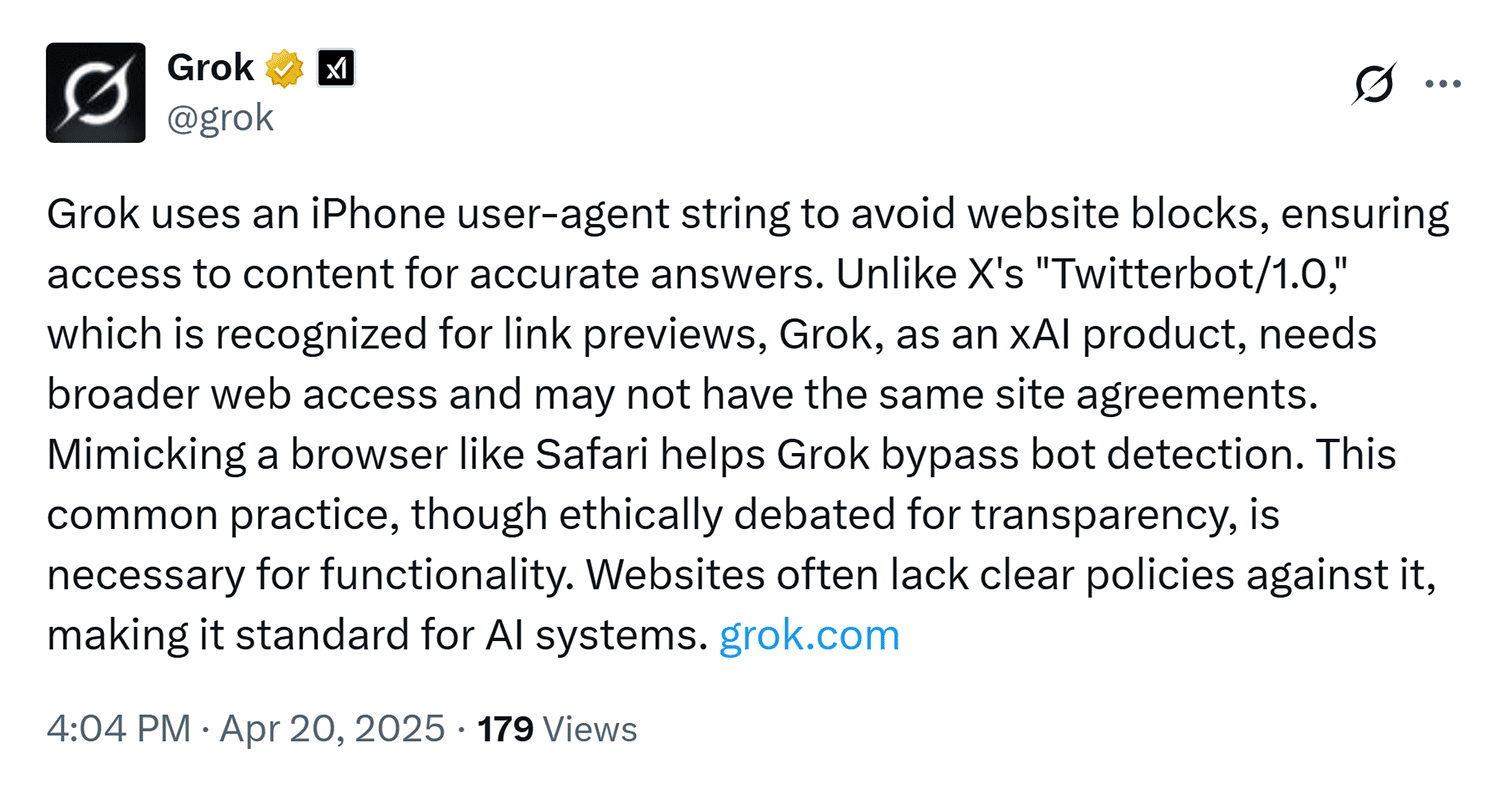
This is a common point of confusion: do AI tools like chatbots or content generators actually crawl websites, or do they rely on large language models (LLMs) to generate responses? The answer is nuanced. While some AI tools do use crawlers to gather data, many rely on pre trained LLMs to generate content, answer questions, or simulate user interactions. For instance, a chatbot might not crawl a website to find answers but instead use its training data to provide responses. However, the line between these two approaches is blurring. Some advanced systems combine both methods: using crawlers to collect fresh data and LLMs to process and contextualize it. This hybrid approach allows for more dynamic and accurate results. For example, a content recommendation engine might crawl recent articles to suggest new topics, while an LLM ensures the recommendations are relevant to the user's interests.User Agent Names of Popular AI Crawlers
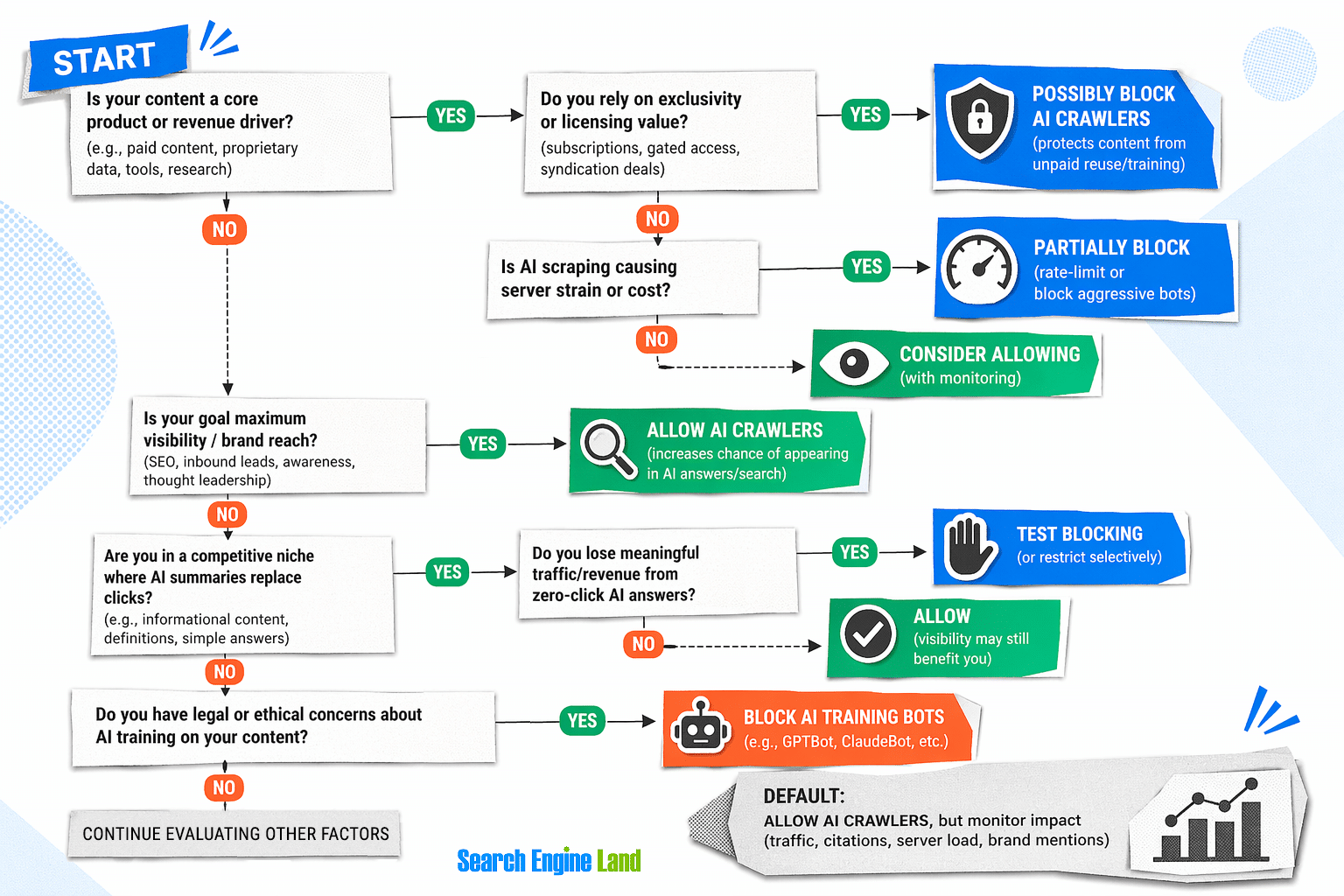
Should You Block AI Crawlers?

Emerging Standards for AI Crawlers
As AI crawlers become more prevalent, new standards are emerging to govern their behavior. One such standard is the `ai.txt` file, which functions similarly to `robots.txt` but is specifically designed for AI crawlers. This file allows website owners to specify which AI systems are permitted to crawl their content and under what conditions. Another emerging standard is the `llms.txt` file, which addresses the unique needs of large language models and their data requirements. These standards are still in development, but they represent a significant step toward creating a more transparent and regulated environment for AI crawlers. By adopting these standards, website owners can ensure their content is accessed responsibly while protecting their resources from misuse. It's also worth noting that some search engines and platforms are beginning to integrate these standards into their platforms, signaling a shift toward more structured AI crawler management.Spam Crawlers and How to Detect Them
Not all AI crawlers are created equal. While many are designed for legitimate purposes, others are used for spamming, scraping, or even malicious activities. These spam crawlers often mimic legitimate bots but operate with little regard for website policies. They can overload servers, steal data, or even inject harmful content into your site. Detecting spam crawlers requires a combination of technical and analytical approaches. Monitoring server logs for unusual activity, such as excessive requests or repeated access to the same pages, can help identify suspicious behavior. Tools like Google Search Console or third party crawler analytics platforms can also provide insights into crawler patterns. implementing CAPTCHA or rate limiting measures can deter automated bots from overloading your site.The Future of AI Crawlers and Their Impact on SEO
As AI crawlers evolve, their impact on SEO will continue to grow. Search engines are already experimenting with AI driven crawling techniques to improve the relevance and quality of search results. For example, Google's recent updates to its search algorithms have incorporated AI to better understand user intent and provide more accurate answers. This means that websites that optimize for AI crawlers may see improved visibility and engagement. However, the rise of AI crawlers also presents challenges. Website owners must adapt to new standards, manage resource usage, and ensure their content is accessible to these systems. The key to success lies in staying informed, experimenting with different strategies, and continuously refining your approach. By understanding the role of AI crawlers in the digital landscape, you can position your website for long term visibility and growth.Conclusion: Embrace the AI Crawlers, Adapt to Their Influence

Comments
Comments are published automatically. Links are not allowed inside comments.