A Practical Way to Use Schema Markup to Optimize for the Agentic Web
/ 10 min read

Summary
In traditional search, schema helps drive visibility by making content more eligible for SERP features and helping search engines. The practical question is what this changes for SEO, content quality, and AI search visibility.

Introduction
The key issue here is Schema markup has earned its place at the center of the SEO and GEO conversation. Google and Bing have confirmed they use structured data to power AI Overviews, and ChatGPT factors it into product recommendations. Now, schema markup is becoming part of the. My read is to treat it as a decision point: what signal needs to become clearer, what part of the system is currently weak, and what evidence would show that the work is improving visibility rather than only adding activity.
That is the difference between reacting to a trend and building a useful search system. Connect this point back to the page template, internal linking, entity signals, content depth, crawl accessibility, and the way the brand is represented across the wider web before deciding what to change first.
The way we interact with the internet is shifting. For decades, we have treated websites as destinations that we visit and browse. But we are moving toward an agentic web, where AI systems do not just find information for us, they interact with websites on our behalf. This shift changes the fundamental goal of technical SEO. It is no longer just about being visible in a list of search results, it is about being usable by an autonomous agent. The same pattern also shows up in X Robots Tag, where the practical question is how the signal becomes visible.
If an AI agent is tasked with booking a flight or finding a specific product, it cannot rely on the same visual cues a human uses. It needs a level of precision that standard HTML cannot provide. This is why schema markup has moved from a nice to have feature to the core infrastructure of the modern web. When Google, Bing, and ChatGPT use structured data to power AI Overviews and product recommendations, they are signaling that the future of the web is structured.
The evolving role of schema in an agentic ecosystem
In the traditional search era, we used schema primarily to win rich snippets or to help a search engine understand that a page was a recipe or a review. The goal was visibility. We wanted the search engine to categorize the entity correctly so it could be served to the right user at the right time. This supported the knowledge graph and influenced how a result looked on a screen. This connects with LLMs & the Low Bar when the same signal needs a clearer operating decision. A useful companion note is to Identify and Prioritize Entity Gaps, because it looks at a nearby part of the same system.
AI agents operate on a different logic. They do not just want to identify an entity, they want to understand the relationships and the relevance of that entity to a specific task. An agent needs to know if a piece of content is trustworthy and actionable enough to actually execute a command. For example, an agent does not just need to know that a product exists, it needs to know if it is in stock and if the price is current before it can recommend it to a user.
There is also a computational reality here. Parsing unstructured HTML is expensive. It requires significant processing power and consumes a large portion of an LLM's context window. Structured data is the path of least resistance. It is cheaper and faster for an AI to read a clean set of properties than to guess the meaning of a div tag. As inference costs and scaling become primary concerns for AI providers, the sites that are easiest to process will naturally be preferred.
Expert Interpretation: The critical shift here is moving from visibility to utility. The tradeoff is that you can no longer rely on "clever" content writing to be discovered. If the data is not structured, the agent may simply skip your site for one that is easier to parse. The decision you need to make is whether to treat schema as a marketing tool for clicks or as a technical API for AI agents.
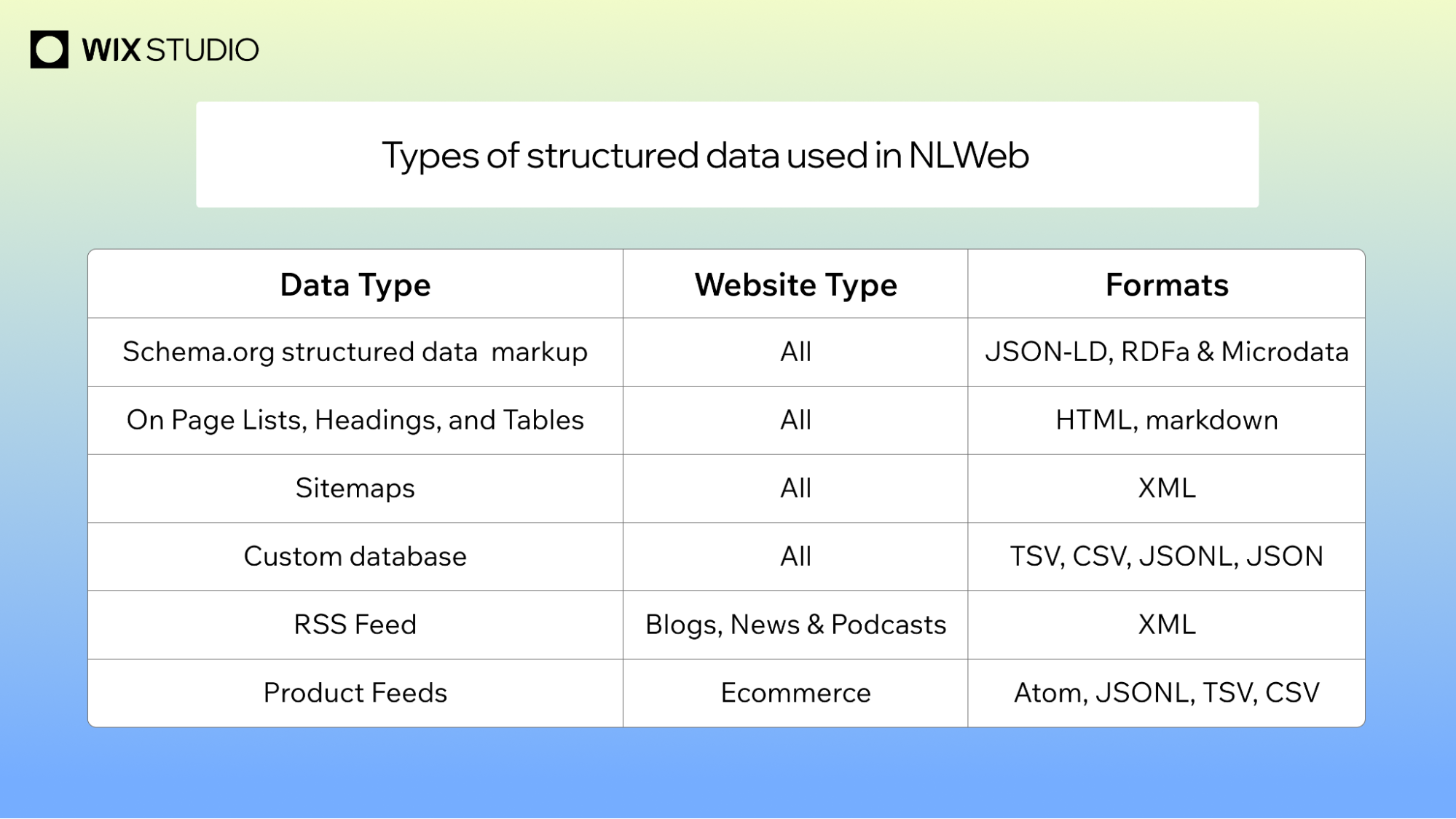
NLWeb and the shift toward queryable websites
If schema is the foundation, then NLWeb is the structure built on top of it. NLWeb is an open source initiative from Microsoft that allows websites to integrate AI powered conversational interfaces. Essentially, it transforms a standard website into an AI application. Instead of a human browsing through a navigation menu, an AI agent can interrogate the site directly using natural language.
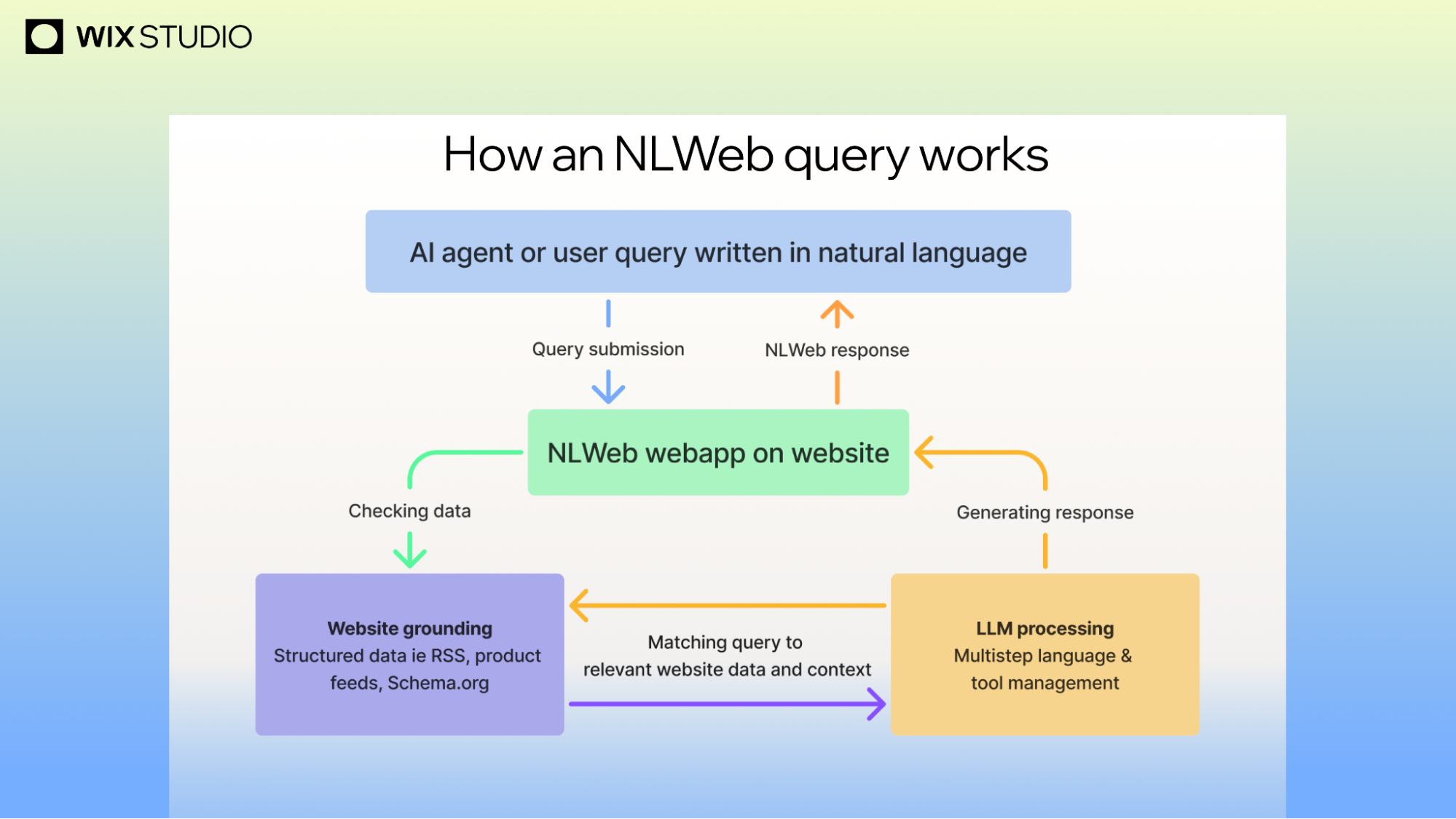
This is the difference between a site that is read and a site that is queryable. A read only site is a brochure. A queryable site is a tool. When a site is truly agentic, an AI can ask a specific question, retrieve a structured answer, and act on that answer without a human ever needing to click a link. To illustrate this, imagine the difference between an agent reading a static restaurant menu and an agent asking if there is a table for four at 7:00 PM tonight and receiving a deterministic, real time answer.
It is worth noting that NLWeb was developed by R.V. Guha, the same person who created RSS, RDF, and Schema.org. The fact that the architect of the web's structured data vocabulary is now building the protocol for AI interaction suggests that this is not a passing trend. It is a fundamental evolution of how data is exchanged between servers and agents.
Expert Interpretation: This matters because it removes the human from the loop. The tradeoff is a loss of control over the user journey. You can no longer guide a user through a carefully designed conversion funnel if an agent is extracting the value and delivering it elsewhere. The decision here is to ensure your structured data is so accurate that the agent's "deterministic" answer is always the correct one, otherwise you risk the agent providing false information about your business.
Practical strategies for agentic schema optimization
Most of us have been using schema for years, but optimizing for agents requires a different mindset. It is less about following a checklist and more about creating a reliable data source.
Prioritize completeness over broad coverage
There is a common temptation to apply thin schema markup across every single page of a site to increase "coverage." For the agentic web, this is a mistake. It is far more valuable to have a few high priority pages with exhaustive, fully populated schema than to have a thousand pages with basic markup.
AI agents look for specific properties to answer user queries. If you have a product page, simply marking it as a "Product" is not enough. The agent needs the price, the availability, the ratings, and the technical specifications. When an agent finds incomplete data, it signals uncertainty. Complete data, on the other hand, signals reliability and trust.
Expert Interpretation: The tradeoff here is between quantity and quality. Many SEOs fear that missing schema on some pages will hurt their rankings. However, for agents, "thin" data is often worse than "no" data because it creates a gap in the logic. You should decide which 20 percent of your pages drive 80 percent of your actionable value and maximize the data depth there first.
Implement automation to ensure consistency
Manual schema management is impossible to scale. For teams without a massive technical SEO budget, the only way forward is automation. Many platforms can now generate markup by default for common page types, such as blog posts, events, or local business info.
The danger here is not a lack of schema, but mismatched data. If your schema tells an agent that a product costs 50 dollars, but the HTML on the page says 60 dollars, the agent will distrust both signals. Consistency is the primary currency of trust for an AI. Agents are more likely to trust a signal that is consistent across the entire site than one that appears sporadically or contradicts itself.
Expert Interpretation: The risk with automation is "set it and forget it" syndrome. The tradeoff is speed versus accuracy. The decision you must inspect is your validation process. Automation is only useful if you have a secondary system to audit the output and ensure the structured data matches the visible content in real time.
use AI to scale complex implementation
While platform automation handles the basics, AI can be used to handle the nuance. You can use AI to analyze your existing content and generate more specific, relevant markup that a standard plugin would miss. This allows you to scale the generation, installation, and validation of structured data across large datasets without needing to write every line of JSON by hand.
Expert Interpretation: The value here is in the "long tail" of your data. The tradeoff is the potential for AI hallucinations in your schema. You should not let AI deploy schema directly to production. The decision should be to use AI for the heavy lifting of drafting the markup, followed by a human or a programmatic validator to ensure the facts are correct.
Stick to JSON LD for programmatic ease
JSON LD is not a new recommendation, but its importance has grown. Because it is separated from the HTML, it is significantly easier for agents to parse programmatically. Google's own guidance emphasizes JSON LD for content that is intended to be AI optimized. It removes the noise of the layout and gives the agent a clean data object to work with.
Expert Interpretation: This is a technical efficiency play. The tradeoff is negligible since JSON LD is widely supported. The decision is simple: if you are still using Microdata or RDFa, you are adding unnecessary friction to the agent's parsing process.
Develop a site level entity graph
Agents do not view pages in isolation. They want to understand how your content connects. They look for the relationship between an article and its author, or a product and its category, and a service and its physical location. You should stop thinking about schema as a page level addition and start thinking of it as a site level graph.
This requires periodic audits at scale. You need to identify where entity definitions conflict across different URLs and ensure that your Organization or Person markup is consistent everywhere. The goal is to provide a coherent picture of your business that an agent can trust regardless of which page it lands on first.
Expert Interpretation: This is the most difficult part of agentic optimization. The tradeoff is the time investment required for a full audit versus the risk of entity confusion. You should inspect your "Organization" and "Person" entities first, as these are the anchors that agents use to establish the authority and trust of the rest of your data.
The window for early mover advantage
AI systems are not starting from scratch every time they crawl. They prefer sources they have already indexed, validated, and found to be reliable through previous interactions. This creates a compounding advantage for early adopters. Content that is agent friendly today builds a reputation for reliability that makes it more likely to be chosen by agents in the future.
Schema has always rewarded those who took it seriously, but the stakes are higher now. In the agentic web, the cost of being ignored is not just a lower ranking, it is being completely invisible to the agents that are making decisions for users. The agents are already crawling your site. The only question is whether they find a clear map or a confusing maze.
2. Automate where you can
The key issue here is Manual schema management doesn't scale, which is a challenge for teams without dedicated technical SEO resources. Some platforms can handle this automatically for key page types, like product pages, blog posts, events, bookings, and local business. My read is to treat it as a decision point: what signal needs to become clearer, what part of the system is currently weak, and what evidence would show that the work is improving visibility rather than only adding activity.
That is the difference between reacting to a trend and building a useful search system. Connect this point back to the page template, internal linking, entity signals, content depth, crawl accessibility, and the way the brand is represented across the wider web before deciding what to change first.
Comments
Comments are published automatically. Links are not allowed inside comments.