Technical SEO Problems That Quietly Limit Growth
/ 8 min read

Summary
A practical view on Technical SEO Problems That Quietly Limit Growth, focused on the signal to inspect, the risk to avoid, and the decision it should change.

Introduction
Advanced technical SEO isn't about fixing broken links. It's about controlling and improving crawl behavior, indexation quality, rendering parity, and entity clarity across both traditional search engines and AI systems. Most experienced SEO teams don't lose rankings because they forgot an XML sitemap. They lose ground because small architectural inefficiencies quietly compound over time. In this guide, you'll find 14.

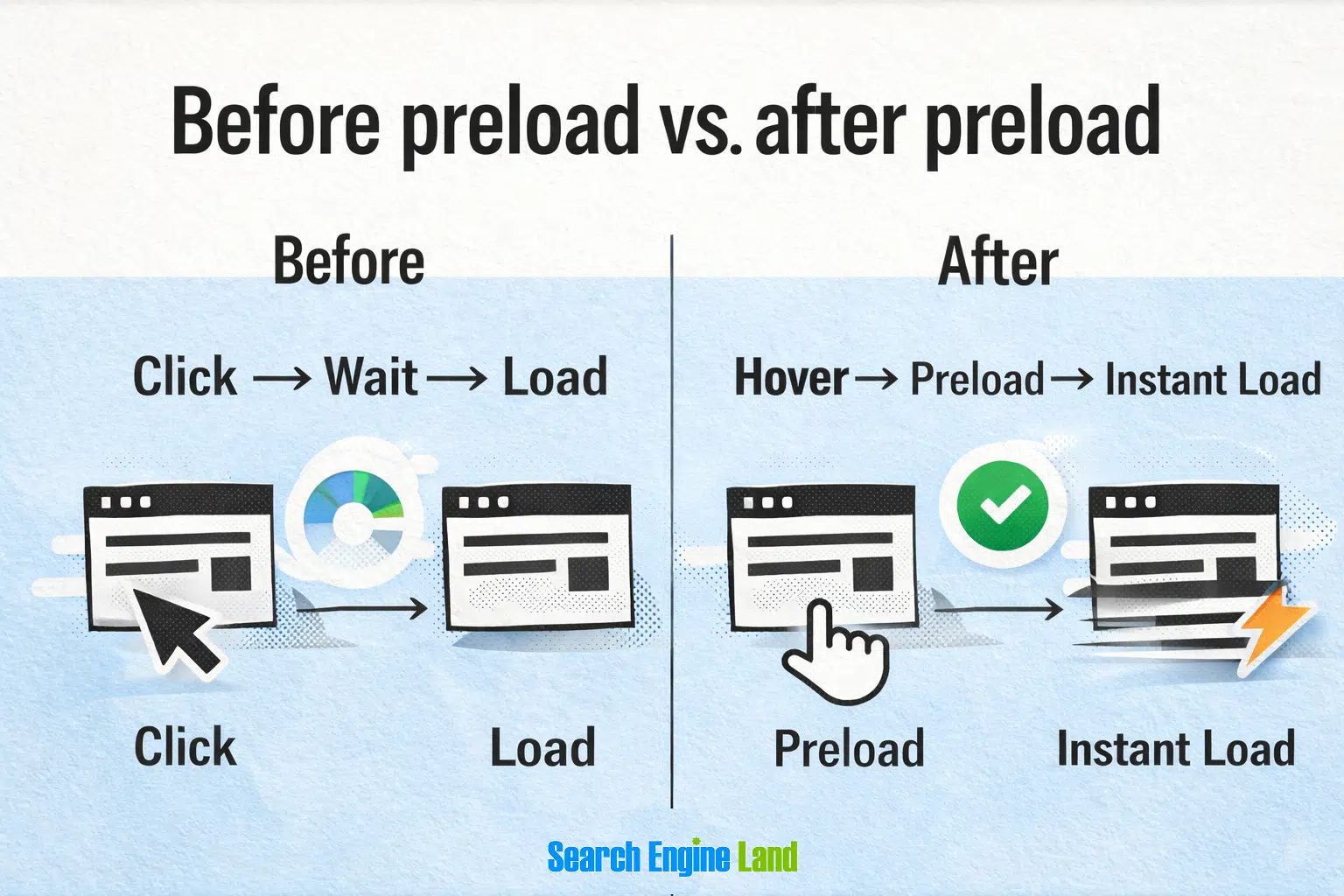
1. Preloading internal links to improve perceived performance
Improving site speed can be complicated. It often requires caching configuration, CSS and JavaScript optimization, minification, lazy loading, DNS prefetching, and removing unused code. That usually means developer time. A Google/Soasta research study reported that as page load time increases from one second to three seconds, bounce probability increases by 32%. At five seconds, it increases by 90%. But not every speed.
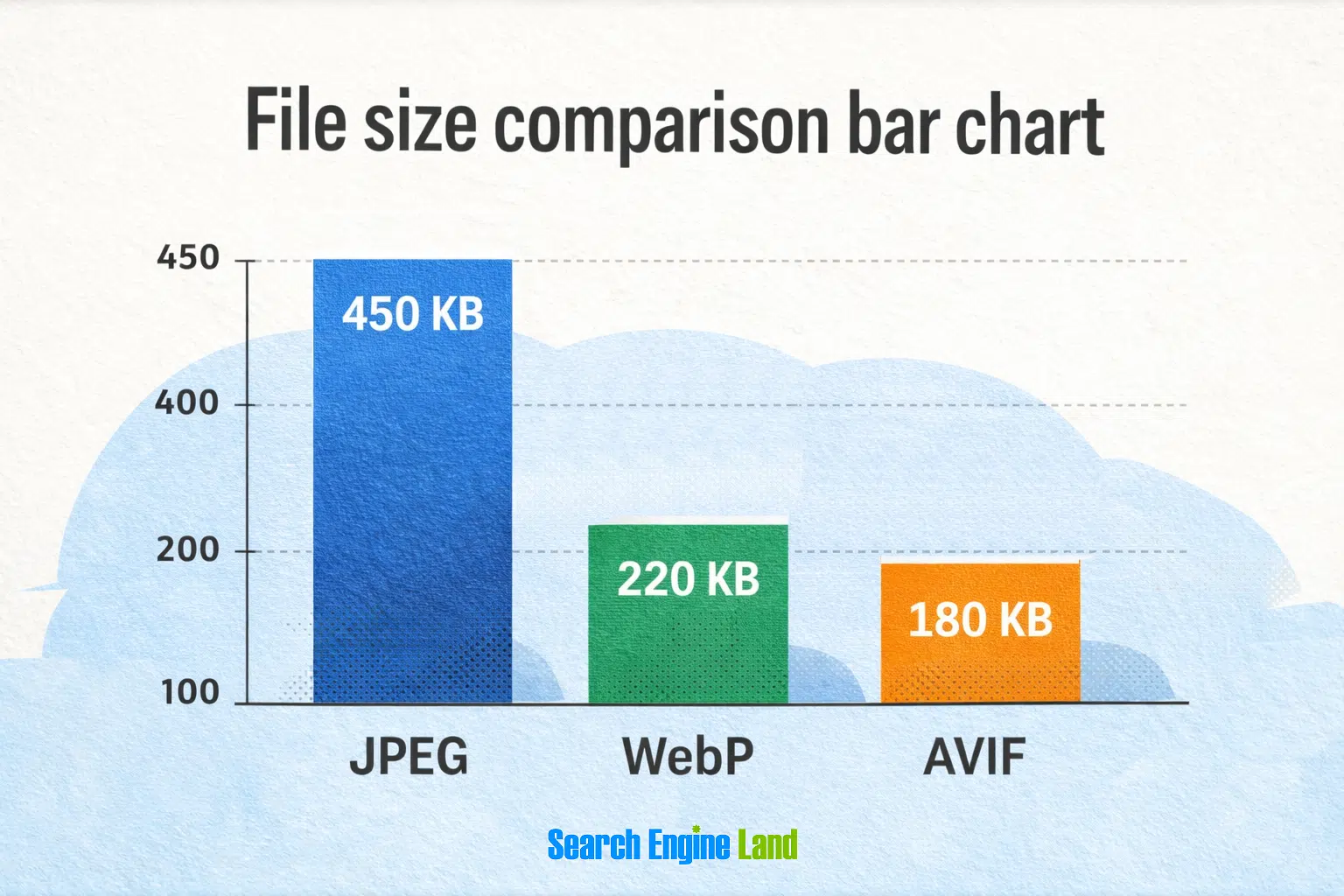
2. Inconsistent use of modern image formats
Image optimization isn't new. Image governance is. That inconsistency creates unnecessary payload bloat. Two modern image formats can cut file size while maintaining quality: Both are designed to reduce file weight without obvious quality loss, but they're not identical: AVIF is newer and often compresses more efficiently (smaller files at similar quality). WebP has broader support and is the safer default for compatibility.
3. AI crawlability gaps in technical audits
Since AI SEO is now an essential consideration, you need to worry about allowing AI crawlers to crawl your site. If they can't access your content, it won't be used in AI search results or AI generated responses (especially if it isn't already in their training data). Traditional technical SEO audits focus on Googlebot. That's no longer enough. AI crawlers such as GPTBot, ClaudeBot, and PerplexityBot behave differently from.
4. Assuming JavaScript rendering is "solved"
Search engine crawlers generally don't have issues crawling JavaScript anymore. This was an issue we previously thought solved that has returned. AI crawlers behave differently from traditional search engine bots. While most of them can fetch JavaScript files, they typically do not execute the code required to render dynamic elements. In practice, this means anything injected into the page after load may never be seen by.

5. Templated pages that scale risk instead of rankings
In SEO, templated web pages are scalable page frameworks where the layout, technical setup, and core components remain fixed while specific data fields change. They're typically used in programmatic SEO to produce large volumes of pages efficiently, but their effectiveness depends entirely on how much unique value is layered onto that shared structure. Quick clarification: We're not talking about website design templates.
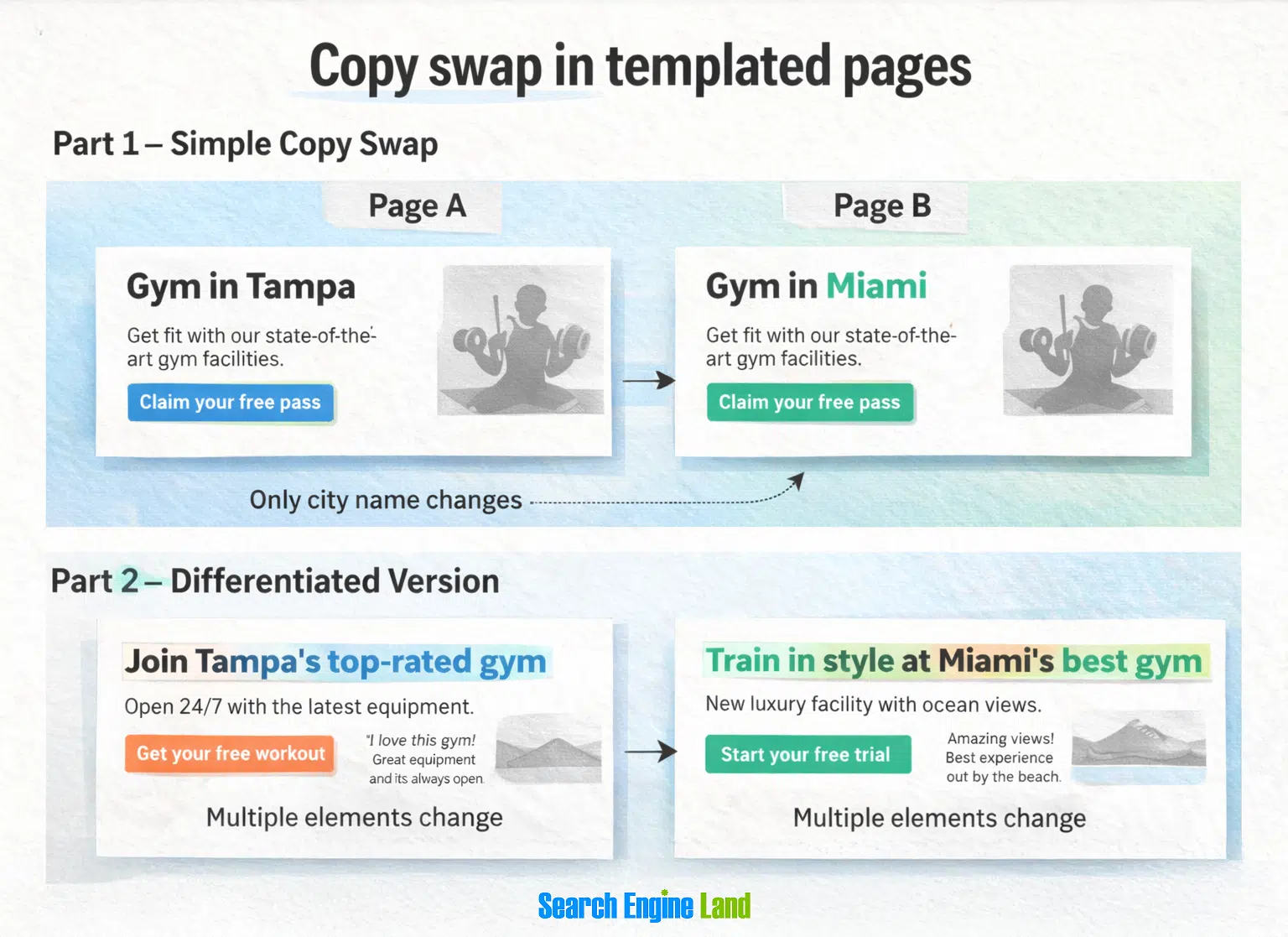
What goes wrong when templated pages are too similar
Duplicate and near duplicate content There is no automatic "duplicate content penalty," as Google has clarified. But near duplicate pages can still underperform. When multiple pages target similar queries with nearly identical content: Google struggles to determine the strongest result The resulting performance isn't due to a penalty. It's algorithmic indifference. Thin or low quality content at scale When pages are.
The fix: How to scale without scaling risk
1. Use deeper variables (not just city swaps) Bad: Looking for pet services in {{city}}? Better: Looking for reliable {{service type}} for your {{pet type}} in {{city}}? More variables create more semantic differentiation. You can manage this in Google Sheets using CONCATENATION formulas and structured inputs. 2. Use controlled variations, not random rewriting AI can help, but only if controlled. One practical method:.
6. Schema audits
Content changes constantly. Schema often doesn't. SEOs tend to implement structured data during a launch and then forget about it. But if your visible content changes, your Schema should reflect those changes, too. Regular Schema audits aren't discussed nearly enough. Review schema remains static while on page reviews change Organization or LocalBusiness schema shows an outdated address Product schema reflects old pricing or. The same pattern also shows up in Product Feeds Now Belong in SEO Strategy, where the practical question is how the signal becomes visible.
7. Schema and knowledge panels
Schema is often used as a CTR tactic for rich results. But schema can also support entity clarity, which can lead to knowledge panels. Important: Schema alone will not create a knowledge panel. It is a foundation, not the entire system. "On its own, Schema Markup is not enough. Google needs a clear description of who you are and what you do as an entity in text format. It needs that information to be corroborated on multiple.
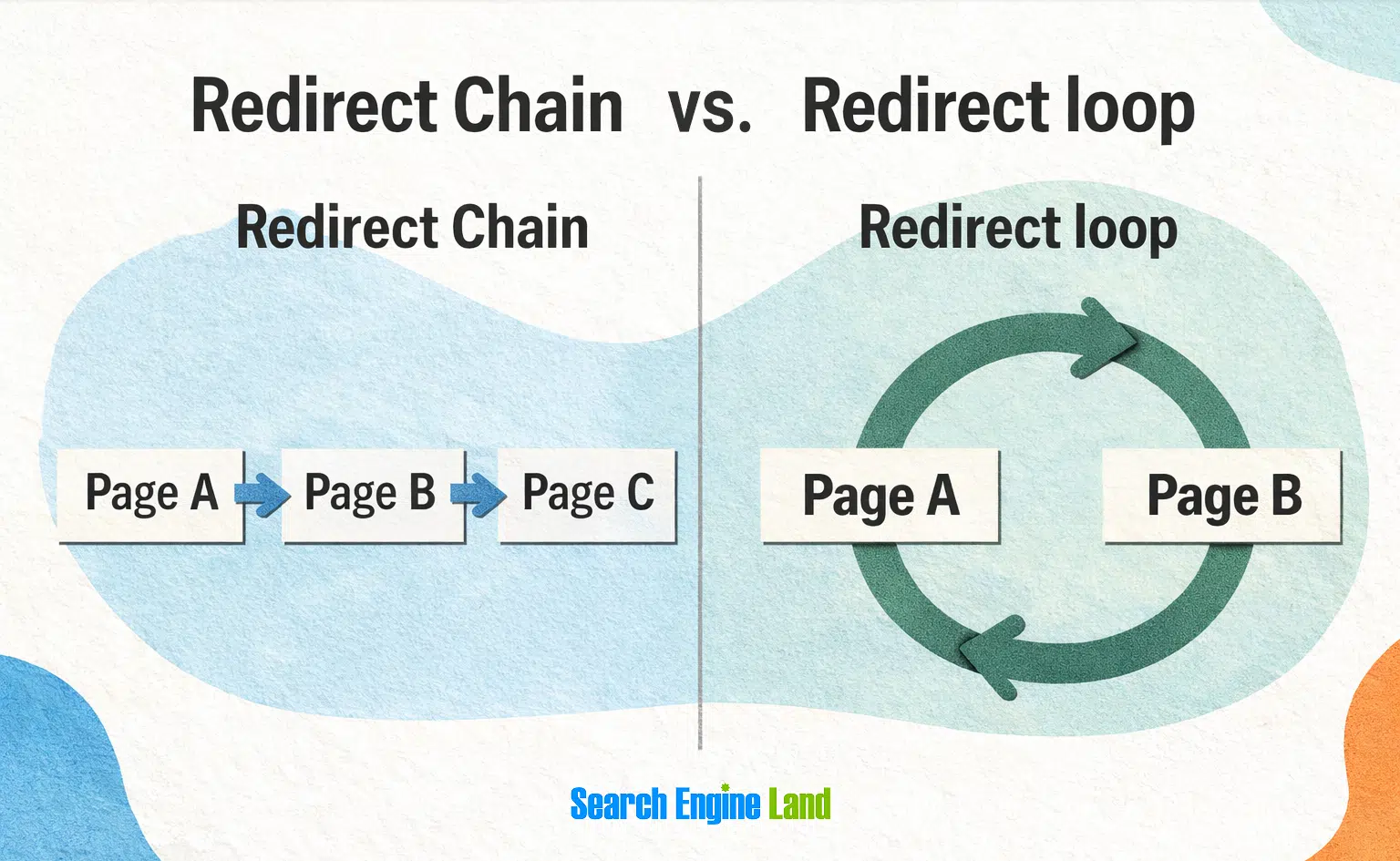
8. Redirect mapping
Everyone knows why redirects are important and how to set them up. But are you tracking your site's redirects? Without governance, sites slowly accumulate: Conflicting redirect rules across the CMS and server That's when you start seeing "too many redirects" errors and crawl inefficiencies. The simplest fix is also the most ignored: maintain a shared redirect map. Document every redirect in a Google Sheet that includes: Any.
9. Infinite spaces
An " infinite space " is what Google calls a huge number of URLs that provide little or no new content. Crawling them wastes bandwidth and can prevent Googlebot from fully indexing real content. On large sites, this risk quickly increases. Infinite spaces can flood the index with low quality variants and waste crawl resources.

Common causes of infinite spaces
According to Google, these are some of the most common causes of infinite spaces: Autogenerated URLs based on site search results Irrelevant parameters, including: Referral parameters These issues often go unnoticed because nothing "breaks." The site still loads, but crawl efficiency quietly deteriorates.
How to fix infinite spaces
Deindex as many problematic URLs as possible Prevent recurrence by changing what generates the URLs Use robots.txt strategically, but not too early Pro tip: It's critical that if you plan to deindex with noindex or via 410 and 404 errors, you don't block crawling first. If Googlebot cannot crawl the pages, it cannot see the noindex or the response code. Let Google crawl them so it can remove them. Then block later, if.
10. Improper canonical tag setup for pagination and sorting parameters
Pagination exists in multiple forms: Pagination: Where a user can use links such as "next," "previous," and page numbers to navigate between pages that display one page of results at a time Load more: Buttons that extend an initial set of displayed results Infinite scroll: Where scrolling triggers additional content loading Canonicals frequently break when parameters like sorting filters are introduced. When done.
Correct canonical setup for paginated pages (no sorting)
The canonical must include the page number parameter Do not canonicalize page 2, 3, and so on back to page 1 Each page in the sequence should be self referencing canonically
Correct canonical setup for pagination with sorting
Sorting parameters quickly complicate things. Canonicals must clearly indicate which URL version should rank, while rel prev/next must preserve the filtered state. The canonical should not include sorting or filtering parameters The rel prev/next should include sorting/filter parameters For deeper technical implementation guidance, this resource from GSQI is the perfect starting point.
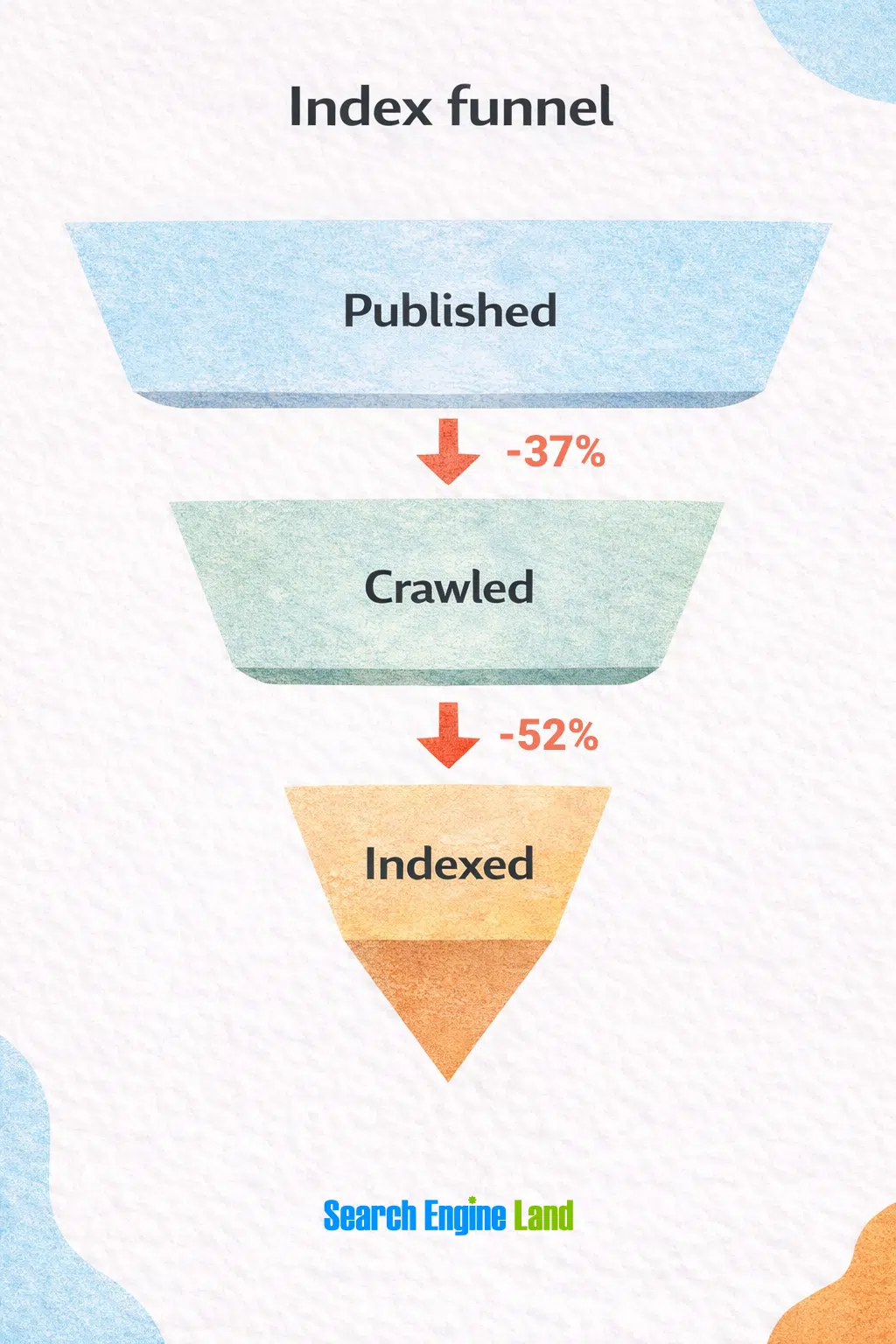
11. New content not getting indexed
Publishing isn't the finish line. Indexing is. When you publish new pages, do you confirm they actually get indexed? Sitemaps and the URL inspection tool in Google Search Console help with discovery, but they do not guarantee indexation. Google has become more selective about indexing. Pages that would have been indexed automatically a few years ago now often take longer or never make it in at all. If pages are not being.
12. Indexed staging sites
Staging sites get indexed in search engine results all the time by mistake. A staging site is typically a development copy of your website used for testing changes. If it's not configured properly, it may not tell search engines to stay out. Confusion over which version should rank Search Google and you'll see how common this is: If your staging site is indexed, it's a problem you must address. All staging environments should. A useful companion note is 6 Ways to Stay Competitive Right Now, because it looks at a nearby part of the same system.
13. Indexed conversion and thank you pages
Thank you pages and conversion pages get indexed in SERPs more frequently than teams realize. Some conversion tracking is based on visits to a thank you page (not all tracking, but common setups). GA4 makes this easy by building an event off page_view. Users can land on them directly from search Example: A user completes a purchase on an Ecommerce site and lands on /order confirmation/. That "page_view" triggers a.
14. URL variants and normalization
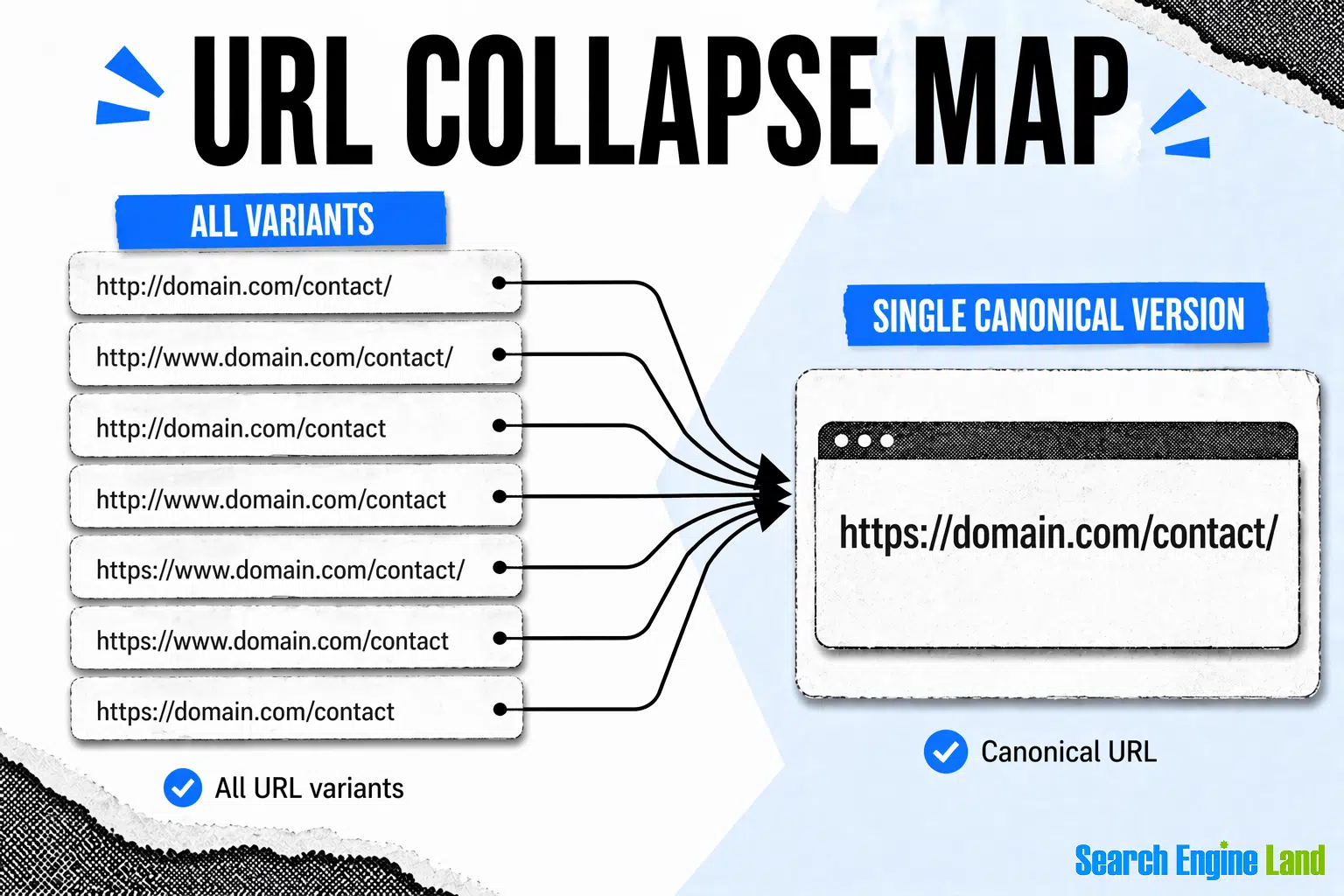
This is a common technical SEO problem where teams still drop the ball: trailing slash vs. no trailing slash Google removed the Preferred Domain setting, and now you must convey your preferred domain via canonical tags, XML sitemaps, and redirects. In addition to those variables, you also have to decide whether to use a trailing slash at the end of each URL. Here's what that can look like for a single path like /services:.
How to fix URL variants and normalize everything
First, decide on your preferred standard: Trailing slash or no trailing slash (pick one) Example preferred structure: https://domain.com/ with trailing slashes. If that's your standard, here's what you need to enforce: 1. Canonical tags must match the preferred version Use canonical tags on each page that point to the correct preferred domain with a trailing slash. Home page canonical = https://domain.com/ Services page.

Strengthen your technical foundation before scaling
Advanced technical SEO isn't about new tactics but about eliminating structural friction. Track, optimize, and win in Google and AI search from one platform. Before scaling content or investing in link building, audit: If you want to streamline this process, enterprise site audit platforms like Semrush One can centralize crawl diagnostics, indexation tracking, and log analysis in one environment. Fix the quiet inefficiencies.
Comments
Comments are published automatically. Links are not allowed inside comments.